Go 调度篇
导读
调度在计算机中是分配工作所需资源的方法. linux的调度为CPU找到可运行的线程. 而Go的调度是为M(线程)找到P(内存, 执行票据)和可运行的G.
首先,带着问题去思考🤔:
- Go的调度为什么说是轻量的?
- Go调度都发生了啥?
- Go的网络和锁会不会阻塞线程?
- 什么时候会阻塞线程?
- Go是怎样实现少量内核线程支撑大量 Goroutine 的并发运行?
- 为了最大限度利用计算资源,Go 调度器是如何处理线程阻塞的场景?
相信你认真阅读完本文,这些问题都会找到答案!
背景常识
调度的进化:Process -> Thread(LWP, lightweight process) -> goroutine (一种 lightweight userspace thread)其实就是一个不断共享, 不断减少切换成本的过程.
理解调度, 首先要理解两个概念: 运行和阻塞
线程其实并不是真正运行的实体, 线程只是代表一个执行流和其状态。真正运行驱动流程往前的其实是 CPU。
线程的运行, 其实是被运行。其阻塞, 其实是切换出调度队列, 不再去调度执行这个执行流。 其他执行流满足其条件, 便会把被移出调度队列的执行流重新放回调度队列,协程也同理。
注意:goroutine 的形式只是协程的一种形式
线程、协程只是一个执行流, 并不是运行实体;
GM 模型(go 1.0)
Go 目前使用的调度器是 2012 年重新设计的,因为之前的 GM 模型调度器性能存在问题,所以使用 4 年就被废弃了;
一个全局队列放待运行的 G 和新生成 G,M 寻找可运行的 G 等操作都在全局队列中操作, 这个过程中需要加线程级别的锁。
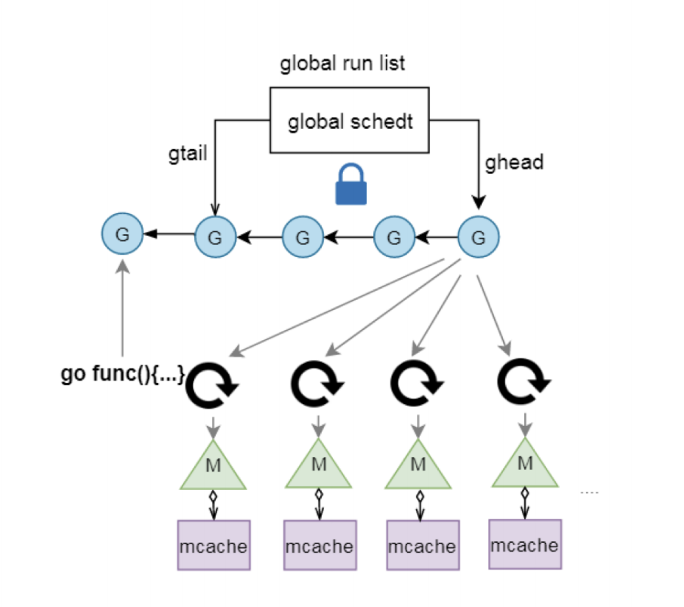
存在的问题
全局调度锁问题
M 想要执行、放回 G 都必须访问全局 G 队列,并且 M 有多个,即:多线程访问同一资源需要加锁进行保证互斥 / 同步,所以全局队列是有互斥锁进行保护的,而单一的全局调度锁(Sched.Lock)和集中的状态,会导致伸缩性下降;
G 的传递问题
M 之间转移 G 会造成延迟和额外的系统负载。比如当 G 中包含创建新协程的时候,M 创建了 G’,为了继续执行 G,需要把 G’交给 M’执行,也造成了很差的局部性,因为 G’和 G 是相关的,最好放在 M 上执行,而不是其他 M’;
Pre-M 的内存问题
每个 M 都需要 memory cache 和其他类型的 cache(比如 stack alloc), 然而实际上只有 M 在运行 Go 代码时才需要这些 Per-M Cache, 阻塞在系统调用的 M 并不需要这些 cache. 正在运行 Go 代码的 M 与进行系统调用的 M 的比例可能高达 1:100, 这造成了很大的内存消耗;
优化思路
- 是不是可以给运行的 M 加个本地队列?
- 是不是可以剥夺阻塞的 M 的 mcache 给其他 M 使用?
GMP 模型(go 1.0+)
进程是资源的最小单位,线程是调度的最小单位。Go 的 runtime 把 G 当作最小调度单位了,那么在加一个资源的最小单位不就得了么,这个时候在 M 和 G 之间的 P 就呼之欲出了。
基本概念
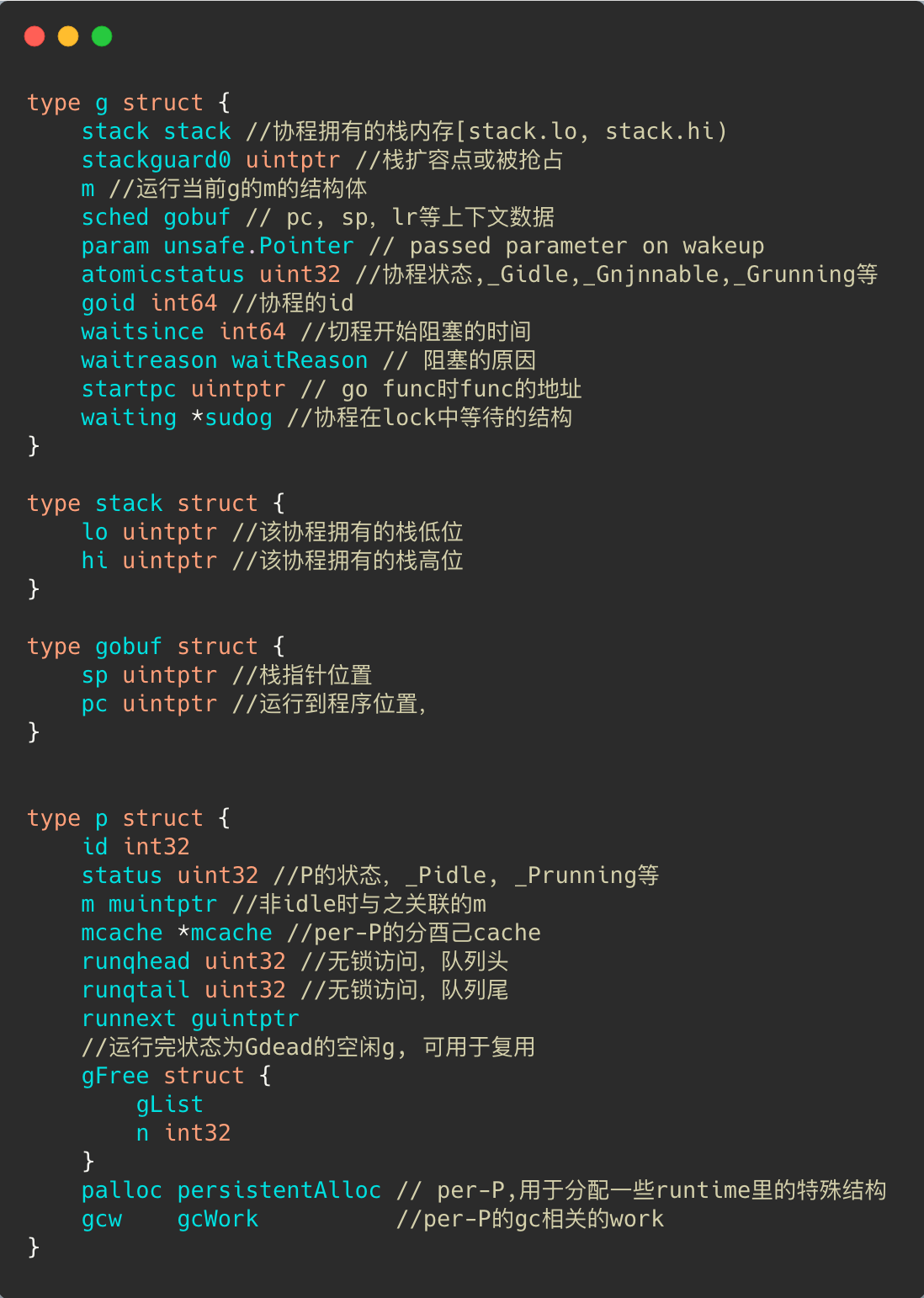
G:goroutine 一个计算任务
M: machine 系统线程,执行实体
P: processor 虚拟处理器
举例说明
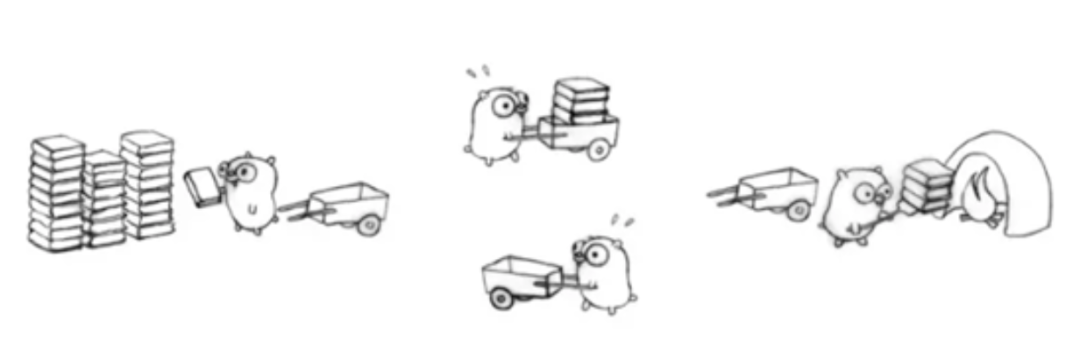
通过经典的地鼠推车搬砖的模型来说明 M、P、G 其三者关系:
地鼠的工作任务是:工地上有若干砖头,地鼠借助小车把砖头运送到火种上去烧制。M 就可以看作图中的地鼠,P 就是小车,G 就是小车里装的砖。
注:地鼠(M) 如果没有小车(P)是没办法运砖的,小车(P)的数量决定了能够干活的地鼠(M)数量,在 Go 程序里面对应的是活动线程数。
全景大图
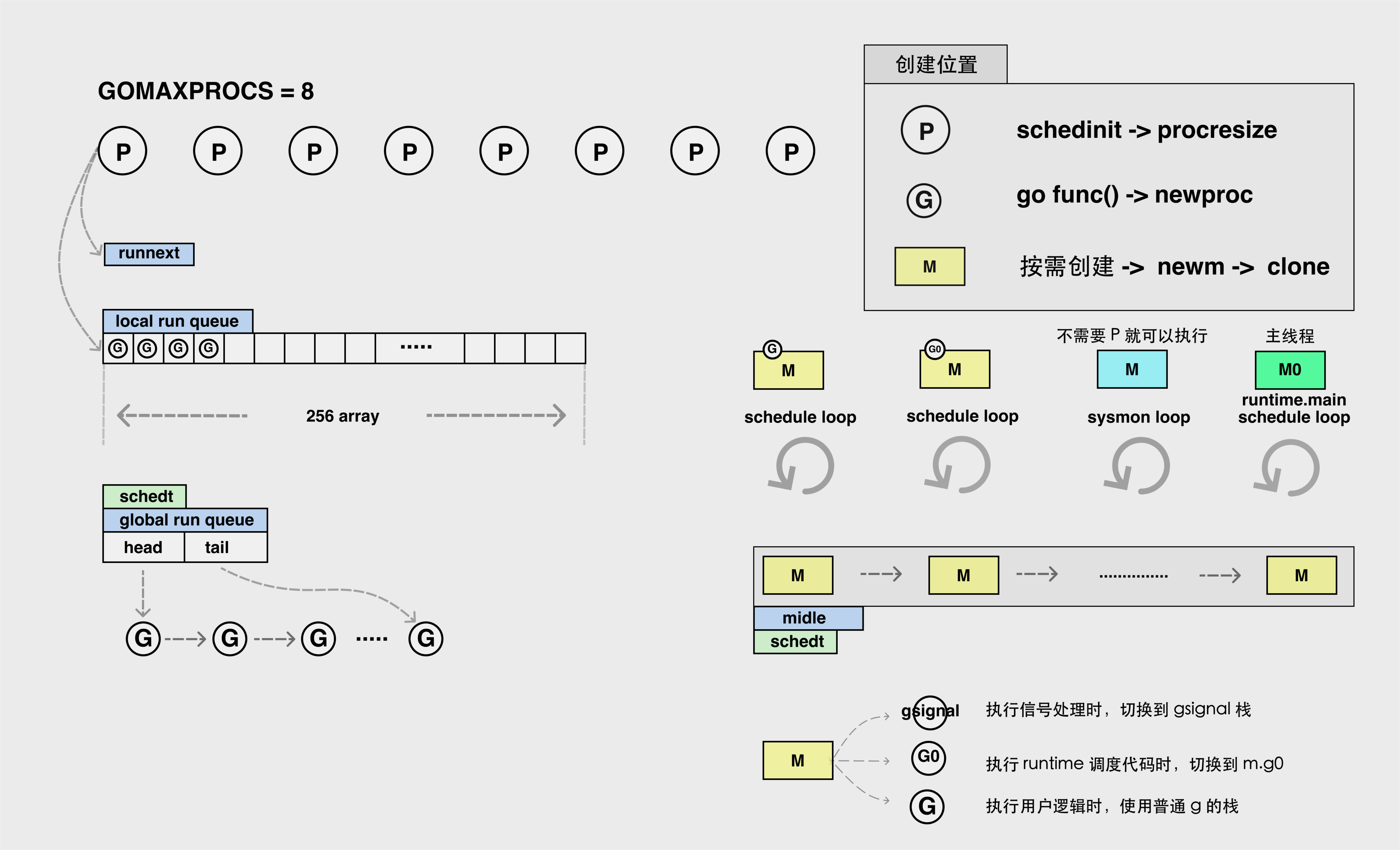
每个 p 均有本地队列,通过增加本地队列减少锁操作:
一个 P 最多包含 257 个 G:一个 126 容量的本地队列 + 优先级最高的 runnext
如果一个 P 上的 G 超过了 257 个,还有一个全局队列,如果超过了就会放在全局队列上,全局队列是个链表,无限长。
相关源码
编译器将 go 关键字编译为生成一个协程结构体
调度器
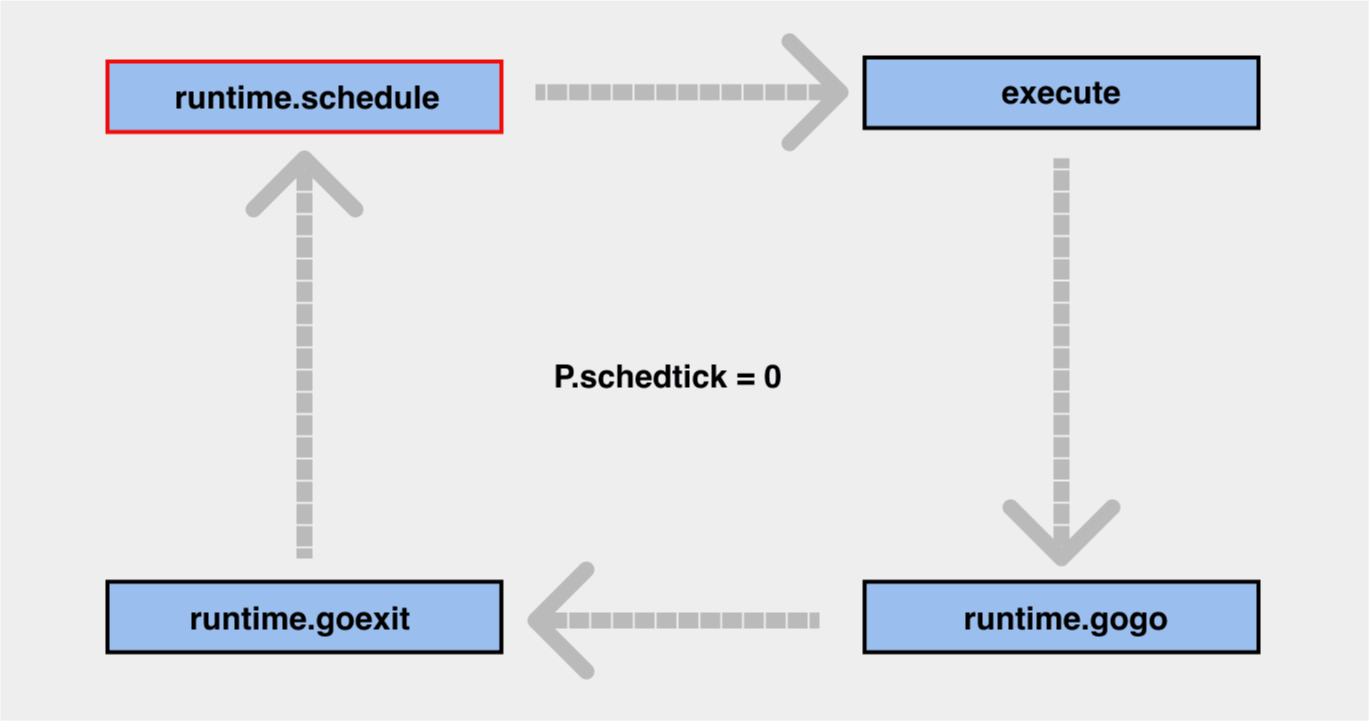
调度循环
M 执行 G 时四个方法周而复始,动态演示图
调度策略
从 P 寻找可用的 G 的具体过程如下,下面逻辑来源于源码中 findrunnable()方法:
如果 P 的 runnext 存在有就用这个 G【不加锁】,如果没有往下做
从 P 的 local queue 中顺序拿一下【不加锁】,如果 local queue 为空没有往下走
从全局队列中拿一个【加锁】,顺便从全局队列拿出 128 个给这个 P(如果全局队列中没有 128 个就都给它,省的以后总来要),如果全区队列为空就继续往下走
从 netpoll 中拿,如果有返回第一个,剩下的通过 injectglist 放到全局队列中【加锁】,如果没有往下走
通过 runqsteal 函数随机从其他的 P 的本地队列中偷一半给当前 P,然后将偷到的最后一个返回,如果还没有,那就算了,将 P 设置为空闲状态并且将 M 从 P 中拿下来,但是不会 kill M。
上面其实涉及了两种调度机制:
- hand off 机制: 当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行,
- work-stealing 机制:当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
调度优化
如果正在执行的 goroutine 阻塞了线程 M 怎么办?P 上 LRQ 中的 goroutine 会获取不到调度么?
主要的 4 种阻塞场景:
场景 1:原子、互斥量或通道操作
调度器将把当前阻塞的 goroutine 切换出去,重新调度 LRQ 上的其他 goroutine;即:用户代码中的协程同步造成的阻塞, 仅仅是切换协程, 而不阻塞线程;
场景 2:调用 sleep 方法
Go 程序后台有一个监控线程 sysmon,它监控那些长时间运行的 G 任务然后设置可以抢占的标识符,别的 goroutine 就可以抢先进来执行。只要下次这个 goroutine 进行函数调用,那么就会被强占,同时也会保护现场,然后重新放入 P 的本地队列里面等待下次执行。
场景 3:调用一些系统方法
这种情况下,进行系统调用的 goroutine 将阻塞当前 M。此时需要调度器的介入。
例如:同步系统调用(如文件 I/O)会导致 M 阻塞的情况,G1 将进行同步系统调用以阻塞 M1。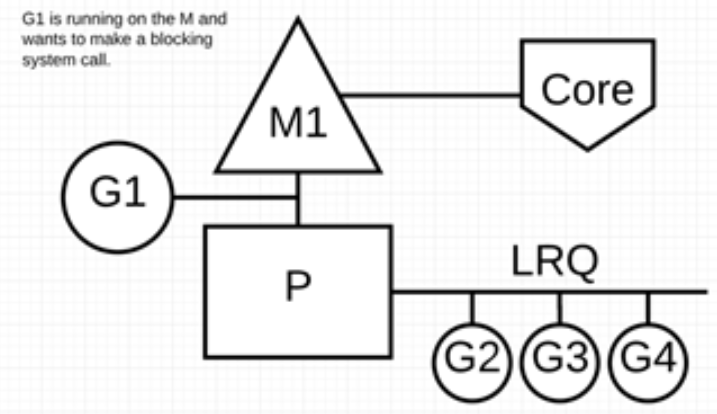
调度器介入后:监控线程 sysmon 识别出 G1 已导致 M1 阻塞,会将 M1 与 P 分离,同时也将 G1 带走。然后调度器引入新的 M2 来服务 P。此时,可以从 LRQ 中选择 G2 并在 M2 上进行上下文切换。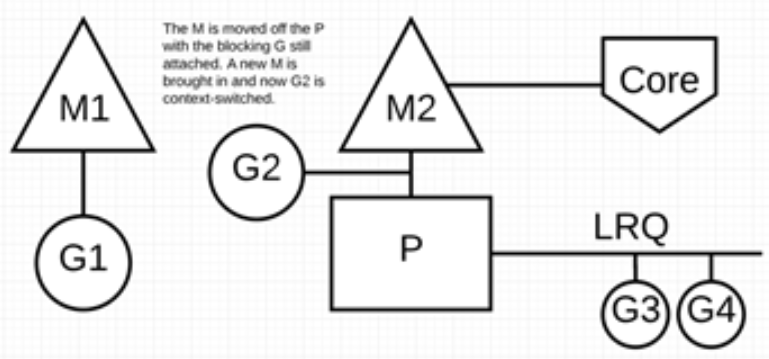
阻塞的系统调用完成后:G1 可以移回 LRQ 并再次由 P 执行。为防止这种情况再次发生,M1 将被放在旁边以备将来重复使用。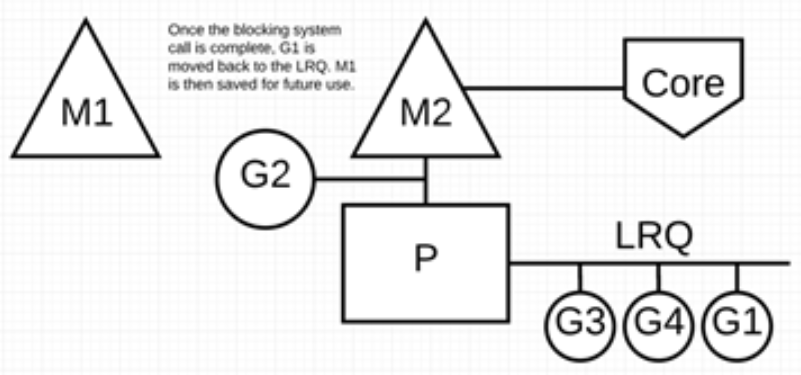
场景 4:网络 IO 请求操作
Go 通过使用**网络轮询器(NetPoller)**进行网络系统调用,防止 goroutine 在进行这些系统调用时阻塞 M。这可以让 M 执行 P 的 LRQ 中其他的 goroutines,而不需要创建新的 M。从而减少操作系统上的调度负载;
下面展示它的工作原理:
G1 正在 M 上执行,还有 3 个 goroutine 在 LRQ 上等待执行。网络轮询器空闲着,什么都没干。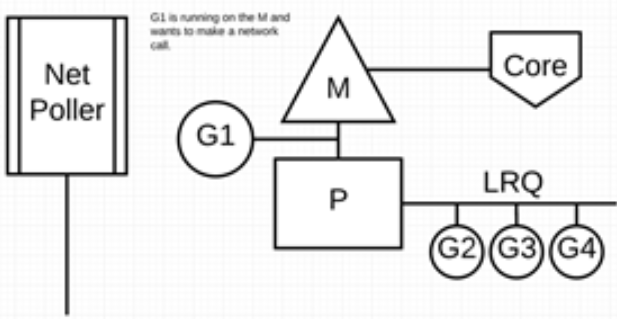
接下来,G1 想要进行网络系统调用,因此它被移动到网络轮询器并且处理异步网络系统调用。然后,M 可以从 LRQ 执行另外的 goroutine。此时,G2 就被上下文切换到 M 上了。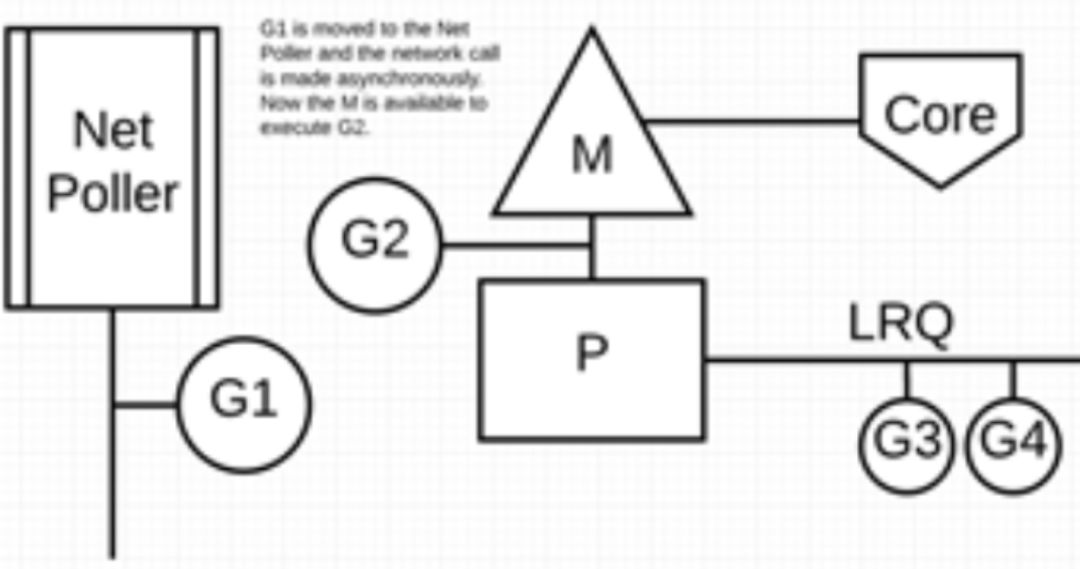
最后,异步网络系统调用由网络轮询器完成,G1 被移回到 P 的 LRQ 中。一旦 G1 可以在 M 上进行上下文切换,它负责的 Go 相关代码就可以再次执行。这里的最大优势是,执行网络系统调用不需要额外的 M。网络轮询器使用系统线程,它时刻处理一个有效的事件循环。

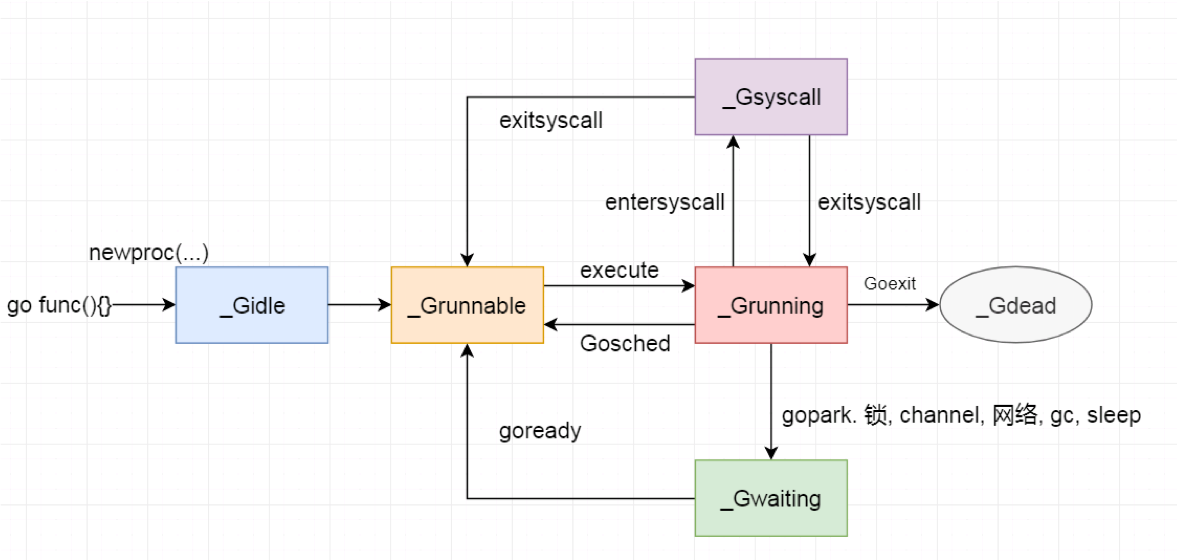
G 状态流转
G 状态列表

G 状态流转图
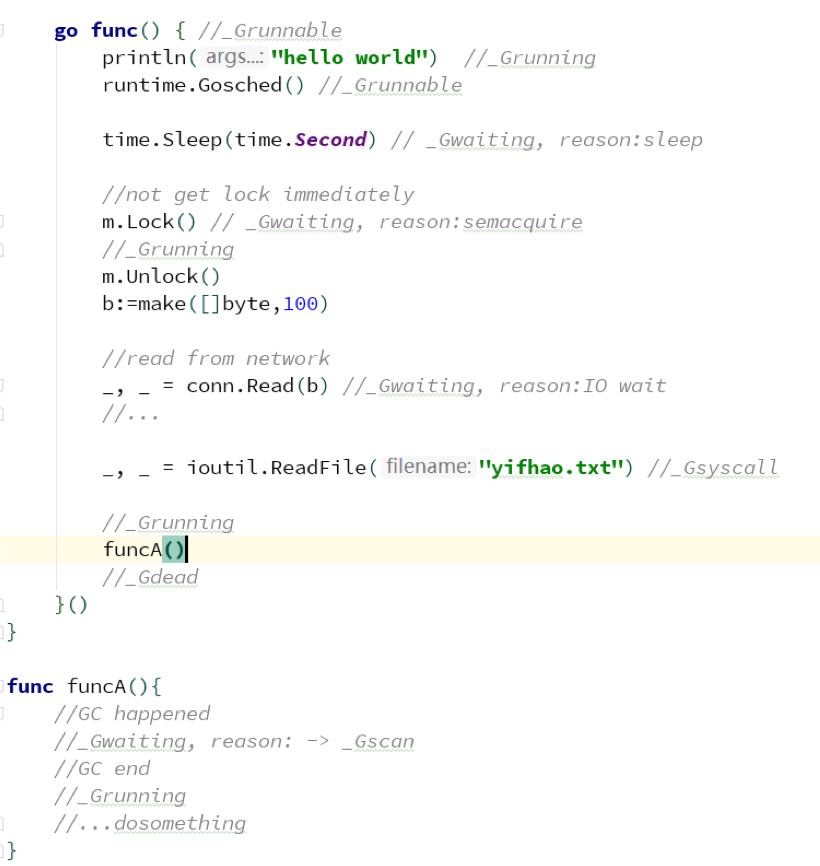
举例说明
G 抢占(Preemption)
抢占的触发时机
- GC STW
- 栈扫描
- 后台监控
应用案例
为什么 Go 服务容器化之后延迟变高?
现象:被容器限制了 4C 的服务跑在 96C 的机器上,相比于物理机部署的延时高了很多。
原因:因为 Go 启动的时候读的宿主机的 CPU 核心数,启动了 96 个 P,96 个 P 都在找 G 去执行但是只有 4C 的处理时间,导致大量 CPU 耗费在找 G 和上下文切换。
解决方案:引入 uber 的 automaxprocs 库
Go 服务最好不要用太多的 CPU
因为创建的系统线程不会被kill,如果开启 100 系统线程空闲之后,那岂不是这个 100 个系统线程都不会被 kill 就在那静静的等着。因此 Go 服务最好不要用太多的 CPU,几百个线程就将近一个 G 的内存了,你这台机器要是再部署多个就尴尬了。
其他
本文相关 脑图分享:https://www.processon.com/view/link/604ef417e0b34d1578d9ddb6
本文相关 PPT 分享:https://yuque.antfin.com/zhaojinxin.zjx/fy19pc/zdtmxw