Go JSON 三方包哪家强?
引言
为了小伙伴理解,汇总了一下文章中会提及的术语名词解释,请耐心品读,欢迎一起讨论交流!
| 专业术语 | 名词解释 |
|---|---|
| JIT | 即时编译 |
| code-gen | 代码生成 |
| lazy-load | 按需加载/懒加载 |
| ast | 抽象语法树(Abstract Syntax Tree ) |
| Clang | 它是一个 C/C++ 的轻量级编译器 |
| asm | 汇编语言(Assembly language) |
| Plan9 | 它是一个 Unix 系统,其中 Go 底层使用的汇编语言是 plan9 汇编 |
| SIMD | 全称单指令流多数据流(Single-Instruction-Multi-Data)它是一组特殊的 CPU 指令,用于矢量数据的并行处理 |
你真的了解 Go 标准库吗?
问题一:标准库可以反序列化普通的字符串吗?执行下面的代码会报错吗?
1 | var s string |
解:其实标准库解析不仅支持是对象、数组,同时也可以是字符串、数值、布尔值以及空值,但需要注意,上面字符串中的双引号不能缺,否则将不是一个合法的 json 序列,会返回错误。
问题二:如果结构体的 json tag 定义与 key 大小不一致,可以反序列化成功吗?
1 | cert := struct { |
解:如果遇到大小写问题,标准库会尽可能地进行大小写转换,即:一个 key 与结构体中的定义不同,但忽略大小写后是相同的,那么依然能够为字段赋值
为什么使用第三方库,标准库有哪些不足?
Go json 标准库 encoding/json已经是提供了足够舒适的 json 处理工具,广受 Go 开发者的好评,但还是存在以下两点问题:
- API 不够灵活:如没有提供按需加载机制等;
- 性能不太高:标准库大量使用反射获取值,首先 Go 的反射本身性能较差,较耗费 CPU 配置;其次频繁分配对象,也会带来内存分配和 GC 的开销;
因业务使用场景和降本收益等诉求,不可避免需要引入合适的第三方库。
评测三方库
下面开始灵魂三问:
- 热门的三方库有哪些?
- 内部实现原理是什么?
- 如何结合业务去选型?
下面是收集整理的一些开源第三方库,也欢迎有兴趣的小伙伴一起交流补充!
| 库名 | encoder | decoder | compatible | star 数 (2023.04.19) | 社区维护性 |
|---|---|---|---|---|---|
| StdLib(encoding/json) | ✔️ | ✔️ | N/A | - | - |
| FastJson(valyala/fastjson) | ✔️ | ✔️ | ❌ | 1.9k | 较差 |
| GJson(tidwall/gjson) | ✔️ | ✔️ | ❌ | 12.1k | 较好 |
| JsonParser(buger/jsonparser) | ✔️ | ✔️ | ❌ | 5k | 较差 |
| JsonIter(json-iterator/go) | ✔️ | ✔️ | 部分兼容 | 12.1k | 较差 |
| GoJson(goccy/go-json) | ✔️ | ✔️ | ✔️ | 2.2k | 较好 |
| EasyJson(mailru/easyjson) | ✔️ | ✔️ | ❌ | 4.1k | 较差 |
| Sonic(bytedance/sonic) | ✔️ | ✔️ | ✔️ | 4.1k | 较好 |
评判标准
评判标准包含三个维度:
- 性能:内部实现原理是什么,是否使用反射机制;
- 稳定性:考虑到要投入生产使用,必须是一个较为稳定的三方库;
- 功能灵活性:是否支持 Unmarshal 到 map 或 struct,是否提供的一些定制化抽取的 API;
在功能划分上,根据主流 json 库 API,将它们的使用方式分为三种:
- 泛型(generic)编解码:json 没有对应的 schema,只能依据自描述语义将读取到的 value 解释为对应语言的运行时对象,例如:json object 转化为 Go map[string]interface{};
- 定型(binding)编解码:json 有对应的 schema,可以同时结合模型定义(Go struct)与 json 语法,将读取到的 value 绑定到对应的模型字段上去,同时完成数据解析与校验;
- 查找(get)& 修改(set):指定某种规则的查找路径(一般是 key 与 index 的集合),获取需要的那部分 json value 并处理。
功能评测
| 相关库 | unmarshal (interface) | unmarshal (struct) | get&set | stream |
|---|---|---|---|---|
| StdLib | ✔️ | ✔️ | ❌ | ✔️ |
| FastJson | ❌ | ❌ | ✔️ | ❌ |
| Gjson | ✔️ | ❌ | ✔️ | ❌ |
| JsonParser | ❌ | ❌ | ✔️ | ❌ |
| EasyJson | - | ✔️ | - | - |
| JsonIter | ✔️ | ❌ | ✔️ | ✔️ |
| GoJson | ✔️ | ✔️ | ❌ | ✔️ |
| Sonic | ✔️ | ✔️ | ✔️ | ✔️ |
特点分析
| 类别 | 备注 | |
|---|---|---|
| 比标准库功能丰富 | 在功能和使用方式上有别于标准库。通过遍历 json 字符串的字节来挨个解析,返回其值 []byte,由业务方自行处理,牺牲了一定的兼容性,但功能上各有特色。 相关库 - FastJson 的 api 操作最简单; - Gjson 提供了模糊查找的功能,自定义程度最高; - JsonParser 可以插入回调函数执行,提供了一定程度上的便利 |
|
| 比标准库性能好 | 通过代码生成的方式,不使用反射,使用上类似 protobuf 为每一个结构体生成序列化的代码,因此具有强入侵性; 相关库:EasyJson |
|
| 比标准库性能较好,且兼容性较好 | 在功能和使用方式上有兼容标准库,且通过尽量减少反射的使用来提高性能。 相关库:JsonIter、GoJson、Sonic… |
性能评测
下面是评测性能时所用的各个包的版本情况,具体的测试代码,可参考benchmark_test ,欢迎友好交流。
| 库名 | version |
|---|---|
| StdLib | v1.19 |
| JsonIter | v1.1.13 |
| GoJson | v0.10.1 |
| Sonic | v1.8.3 |
为什么没有评测 GJson 库呢?
GJson 在单键查找的场景下有很大的优势。这是因为它的查找是通过 lazy-load 实现的,它巧妙地跳过了传递值,有效地减少了很多不必要的解析,但其实跳过也是一种轻量级解析,实际是在处理 json 控制字符“[”、“{”等;然而当涉及到多键查找时,Gjson 做的事比标准库更糟糕,这是其跳过机制的副作用:相同路径查找导致的重复开销。针对它的使用场景,单纯的评测定性编解码和泛型编解码,对 GJson 是不公平的。
根据样本 json 的 key 数量和深度分为三个量级:
评测过程中,需要注意不但要区分泛型编/解码&定型编/解码,而且也要考虑到并发情况下的性能表现,下面是测试代码样例:
1 | func BenchmarkEncoder_Generic_StdLib(b *testing.B) { |
具体的指标数据和统计结果,可参考benchmark_readme ,大体结论如下:
| 库名 | 数据量 | 泛型编码**性能** | 定型编码性能 | 泛型解码 | 定型解码 |
|---|---|---|---|---|---|
| StdLib | 小 | ⭐️ | ⭐️ | ⭐️⭐️ | ⭐️ |
| - | 中 | ⭐️ | ⭐️ | ⭐️ | ⭐️ |
| - | 大 | ⭐️ | ⭐️ | ⭐️ | ⭐️ |
| JsonIter | 小 | ⭐️⭐️⭐️ | ⭐️ | ⭐️⭐️ | ⭐️⭐️⭐️ |
| - | 中 | ⭐️⭐️⭐️ | ⭐️ | ⭐️⭐️ | ⭐️⭐️ |
| - | 大 | ⭐️⭐️⭐️⭐ | ⭐️ | ⭐️⭐️ | ⭐️⭐️ |
| GoJson | 小 | ⭐️⭐️⭐️ | ⭐️⭐️ | ⭐️ | ⭐️⭐️⭐️ |
| - | 中 | ⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
| - | 大 | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
| Sonic | 小 | ⭐️⭐️⭐️⭐ | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
| - | 中 | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
| - | 大 | ⭐️⭐️⭐️⭐ | ⭐️⭐️⭐️⭐ | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
常见优化思路
定型编解码
对于有 schema 的定型编解码场景而言,很多运算其实不需要在“运行时”执行。例如业务模型中确定了某个 json key 的值一定是布尔类型,其实可以在序列化阶段直接输出这个对象对应的 json 值(true/false),并不需要再检查这个对象的具体类型。其核心思想是优化数据处理逻辑,将模型解释与数据处理逻辑分离,让前者提前固定下来,进而消除反射,提升性能。
动态函数组装
JsonIter 就使用函数组装模式,具体方法是将结构解释为逐个字段的编码和解码函数,然后将其组装并缓存为整个对象对应的编解码器,运行时再加载出来处理 json,将反射的性能损失成本降到最低。
这样优化是否就能一劳永逸呢?
并没有。因为这样实现会转化为大量的接口封装和函数调用栈。在实际测试中,会发现随着 json 数据量级的增长,因为调用接口涉及动态寻址,汇编函数不能被内联,而 Golang 的函数调用性能很差(没有逐个寄存器的参数传递),函数调用的开销也会成倍放大。
减少函数调用
为了避免动态汇编的函数调用开销,业界实现方式目前主要有两种:code-gen(代码生成 ) 和 JIT( 即时编译)。
code-gen
这种实现方式库开发者实现起来相对简单,性能高,但是它伴随着模式依赖性和便利性的损失,增加业务代码的维护成本和局限性,无法做到秒级热更新,这也是代码生成方式的 json 库受众并不广泛的原因。例如 EasyJson 就采用代码生成的思路。
JIT
即时编译将编译过程移到了程序的加载或首次解析阶段,只需要提供 json schema 对应的结构体类型信息,就可以一次性编译生成对应的编解码器,通常以 Golang 函数的形式缓存到堆外内存,便于后期高效执行。
1 | // 函数缓存 |
泛型编解码
其实泛型编解码性能差只是因为没有 schema ,因为可以对比一下 C++ 的 json 库,如 simdjson,它的解析方式都是泛型的,但性能仍然很好;
Go 标准库泛型解析性能差,原因在于它采用了 map[string]interface{} 作为 json 的编解码对象。这其实是一种糟糕的选择,原因如下:
- 数据反序列化的过程中,map 插入的开销很高;
- 在数据序列化过程中,map 遍历也远不如数组高效;
如果用一种与 json AST 更贴近的数据结构来描述,不但可以让转换过程更加简单,甚至可以实现 lazy-load 。
复用编码缓存区
通过使用 sync.Pool 复用先前编码的缓冲区,可以有效减少 encode buffer 的内存分配次数。
1 | type buffer struct { |
案例 Sonic 库
原理调研
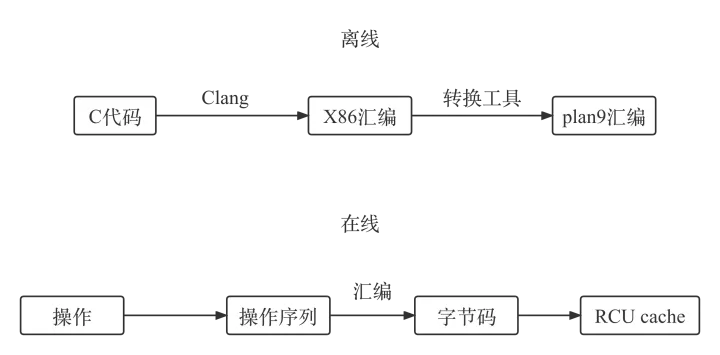
Sonic 基于汇编进行开发,通过充分利用向量化(SIMD)指令、优化内存布局和按需解析等关键技术,大幅提高了序列化反序列化性能。针对 Go 语言编译优化的不足,Sonic 核心计算函数使用 C 语言编写,使用 Clang 的深度优化编译选项,并开发了一套 asm2asm 工具,将完全优化的 x86 汇编翻译成 plan9 汇编,加载到 Golang 运行时,以供调用。
为什么不使用 CGO ?
虽然使用 CGO 实现更加简便, 但 CGO 在调用 c 代码的时候引入了调度、切换线程栈等开销,会造成较大(有的场景中高达 20 多倍)的性能损耗,无法对代码进行了深度优化。
SIMD
什么是 SIMD?
SIMD(Single-Instruction-Multi-Data 单指令流多数据流)它是一种采用一个控制器来控制多个处理器,同时对一组数据中的每一个数据分别执行相同的操作,从而实现空间上的并行性技术。例如:X86 的 SSE 或者 AVX2 指令集,以及 ARM 的 NEON 指令集等。它作为一组特殊的 CPU 指令,用于矢量数据的并行处理。目前,它被大多数 CPU 所支持,并广泛用于图像处理和大数据计算中,当然在 json 处理中也很有用。
SIMD 在 json 处理中解决了什么问题?
对于 json 文本的处理与计算。其中一些问题在业界已经有比较成熟高效的解决方案,如浮点数转字符串算法 Ryu,整数转字符串的查表法等;针对一些问题逻辑相对简单,但是可能会面对较大数量级的文本,如 json string 的 unquote\quote 处理、空白字符的跳过等,也需要某种技术手段来提升处理能力,而 SIMD 就是一种用于并行处理大规模数据的技术。simdjson-go在大型 json 场景(>100KB)中非常有竞争力。然而,对于一些极小的或不规则的字符串,SIMD 所需的额外负载操作将导致性能下降。因此, 对于大数据和小数据并存的实际场景,采用预设条件判断(字符串大小、浮动精度等),将 SIMD 和标量指令结合起来,以达到最佳适应性。
asm2asm
为了提高执行效率,Sonic 中一些关键的计算函数是用 C 编写的,用 Clang 编译的;但由于 Clang 编译出来的是 x86 汇编,而 Golang 编译出来的是 plan9 汇编;那如何将优化后的汇编嵌入 Golang 中就变成了一个问题,因此为了在 Golang 中调用 Clang 编译出来的汇编,字节开发了一个内部工具 tools/asm2asm 将 x86 的汇编转换为 plan9。
JIT 汇编
Sonic 借鉴 JsonIter 的组装各类型处理函数的实现,针对编解码器动态装配的函数调用开销,采用 JIT 技术在运行时对模式对应的操作码(asm)进行装配,最后以 Golang 函数的形式缓存到堆外内存。因为编译后的编解码函数是一个集成函数,可以大大减少函数调用,同时保证灵活性;对于 json 对应的结构体已知的服务场景,在线进行 JIT 汇编是比较耗时的,会导致首次请求耗时较高,也可以预先生成好汇编后的字节码。
RCU cache
为了提升 Codec Cache 的加载速度,每个结构体对应的序列化/反序列化字节码可以缓存起来,后面直接调用,以减少运行时汇编操作的执行次数(缓存足够大的时候只需要执行一次)。Sync.Map 最初是用来缓存编解码器的,但对于准静态(读远多于写)、较少元素(通常不超过几十个)的场景来说,其性能并不理想,所以用“开放寻址哈希+RCU 技术”重新实现了一个高性能和并发安全的缓存。
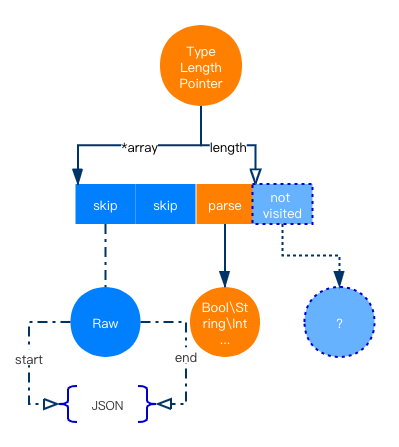
自定义 AST
针对泛型编解码,基于 map 开销较大的考虑,Sonic 实现了更能符合 json 结构的树形 AST;通过自定义的一种通用的泛型数据容器 sonic-ast 替代 Go interface,从而提升性能。用 node {type, length, pointer} 表示任意一个 json 数据节点,并结合树与数组结构描述节点之间的层级关系。针对部分解析,考虑到解析和跳过之间的巨大速度差距,将 lazy-load 机制到 AST 解析器中,以一种更加自适应和高效的方式来减少多键查询的开销。
1 | type Node struct { |
如何实现部分解析? sonic-ast 实现了一种有状态、可伸缩的 json 解析过程。当使用者 get 某个 key 时,采用 skip 计算来轻量化跳过要获取的 key 之前的 json 文本;对于该 key 之后的 json 节点,直接不做任何的解析处理;仅使用者真正需要的 key 才完全解析。另外,在对于子节点 skip 处理过程增加了一个步骤,将跳过 json 的 key、起始位、结束位记录下来,分配一个 Raw-JSON 类型的节点保存下来,这样二次 skip 就可以直接基于节点的 offset 进行,这样解决相同路径查找导致的重复开销的问题。同时 sonic-ast 支持了节点的更新、插入和序列化,甚至支持将任意 Go types 转为节点并保存下来。
函数调用优化
- 无栈内存管理:自己维护变量栈(内存池),避免 Go 函数栈扩展。
- 自动生成跳转表,加速 generic decoding 的分支跳转。
- 使用寄存器传参:将使用频繁的变量放到固定的寄存器上(如 json buffer、结构体指针),尽量避免 memory load & store。
- 重写函数调用:由于汇编函数不能内联到 Go 函数中,函数调用引入的开销甚至会抵消 SIMD 带来的性能提升,因此在 JIT 中重新实现了一组轻量级的函数调用(维护全局函数表+函数 offset)。
业务实践
适用场景
由于 Sonic 优化的是 json 操作,所以在 json 操作的 cpu 开销占比较大的服务场景中收益会比较明显。比如网关、转发和入口服务等。
快速试用
为了较小侵入地验证 Sonic 会对服务产生的性能提升,评估是否值得切换。推荐使用brahma-adshonor/gohook 工具库,内部大概实现是向被 hook 的函数地址中写入跳转指令,直接跳转到新的函数地址。
使用方式:在 main 函数的入口处 hook 当前使用的 json 库函数为 Sonic 中对等函数。hook 是函数级的,因此可以具体验证具体函数的性能提升;当人出于对某些函数的不信任、或者自己有性能更优异或更稳定的实现,也可以部分函数使用 Sonic。但需要注意,它未经过生产环境验证,建议仅测试使用。
1 | import "github.com/brahma-adshonor/gohook" |
收益情况
截止 2022 年 1 月份,Sonic 已应用于抖音,今日头条等服务,累计为字节节省了数十万核。下图为字节某服务使用 Sonic 后高峰时段的 cpu 占用核数对比(图来源)。在生产环境中,Sonic 中也验证了良好的收益,服务高峰期占用核数减少将近三分之一:
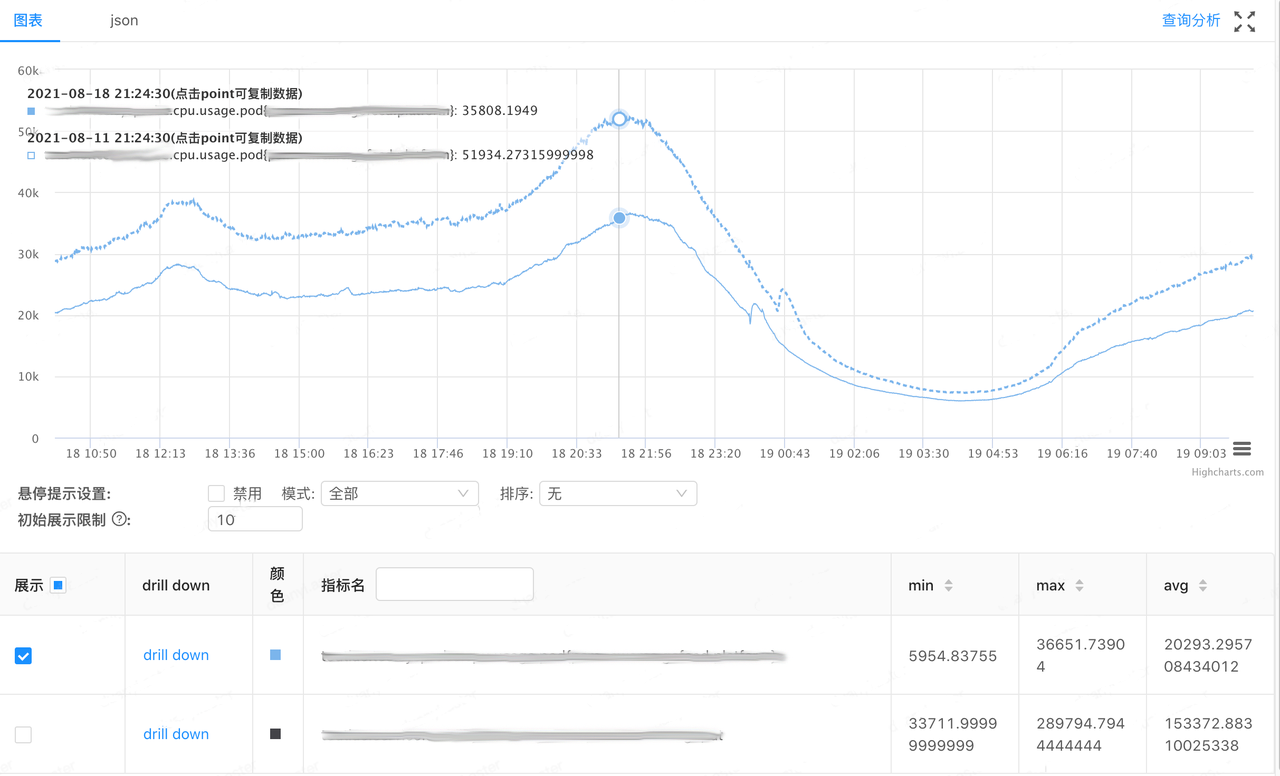
使用事项
HTML Escape
标准库中默认会开启 html Escape,而 Sonic 出于性能损耗默认不开启
1 | func TestEncode(t *testing.T) { |
若需要开启,可以通过下面的方法:
1 | import "github.com/bytedance/sonic/encoder" |
大型模式问题
由于 Sonic 使用 golang-asm 作为 JIT 汇编器,这不太适合运行时编译,因此首次运行大型模式可能会导致请求超时甚至处理 OOM。为了获得更好的稳定性,建议在 Marshal()/Unmarshal()之前使用 Pretouch()来处理大型模式或紧凑内存应用程序。
1 | import ( |
key 排序
Sonic 在序列化时默认是不对 key 进行排序的。json 的规范也与顺序无关,但若需要 json 是有序的,可以在序列化时选择排序的配置,大约会带来 10%的性能损耗。排序方法如下:
1 | import "github.com/bytedance/sonic" |
暂不支持 arm 架构
现象:本地用 Mac M1 无法编译成功解决方案,可参考 sonic-compatibility,在编译时通过添加以下参数: GOARCH=amd64,可解决编译失败的问题,但本地环境依旧没法支持 Debug 操作;
官方在 issue172 中表示考虑到内部实现的确很难搞,但还是有望在 Sonic V2 大版本中支持。
总结
综上,业务选型上需要根据具体情况、不同领域的业务使用场景和发展趋势进行选择,综合考虑各方面因素。 例如:如果业务只是简单的解析 http 请求返回的 json 串的部分字段,并且字段都是确定的,偶尔需要搜索功能,那 Gjson 是很不错的选择。
以下是一些个人观点,仅供参考:
- 不太推荐使用 Jsoniter 库,原因在于: Go 1.8 之前,官方 Json 库的性能就收到多方诟病。不过随着 Go 版本的迭代,标准 json 库的性能也越来越高,Jsonter 的性能优势也越来越窄。如果希望有极致的性能,应该选择 Easyjson 等方案而不是 Jsoniter,而且 Jsoniter 近年已经不活跃了。
- 比较推荐使用 Sonic 库,因不论从性能和功能总体而言,Sonic 的表现的确很亮眼;此外,通过了解 Sonic 的内部实现原理,提供一种对于 cpu 密集性的操作的优化“野路子“,即:通过编写高性能的 C 代码并经过优化编译后供 Golang 直接调用。但其实并不新鲜,因为实际上 Go 源码中的一些 cpu 密集型操作底层就是编译成了汇编后使用的,如:crypto 和 math。