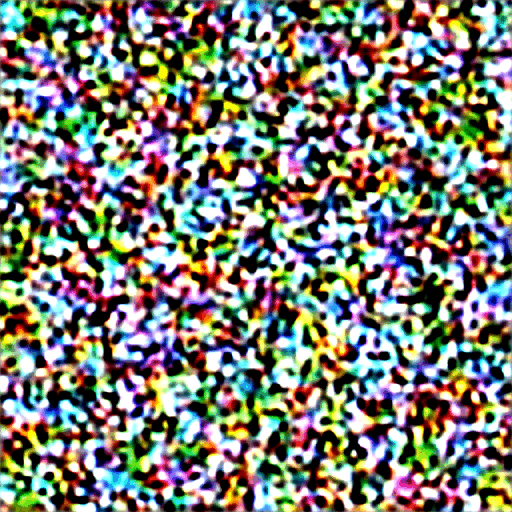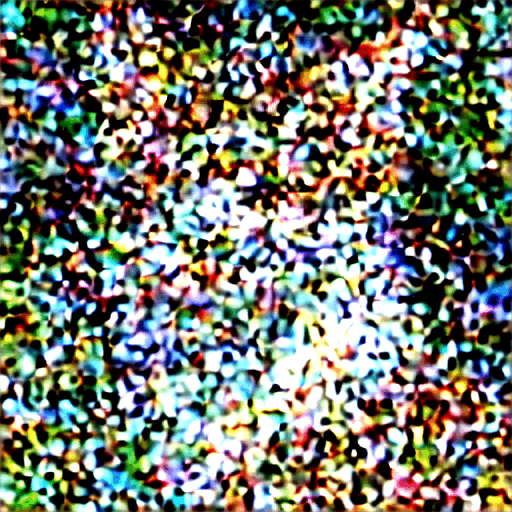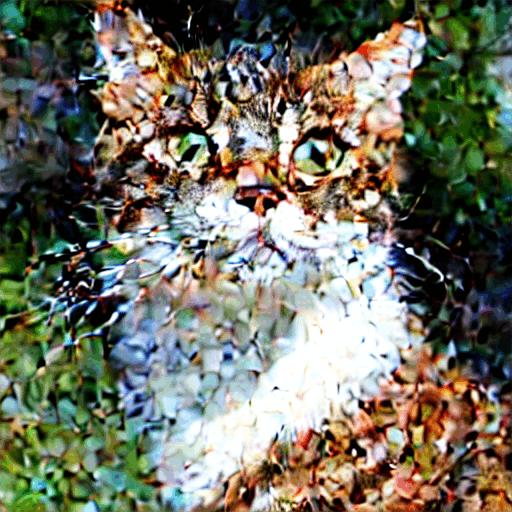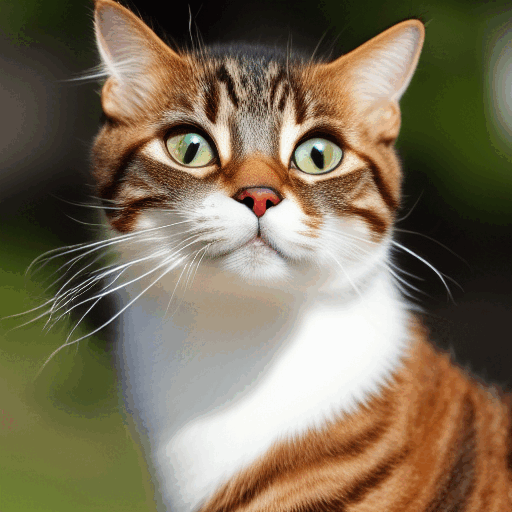白话科普 | AI绘画是如何生成图像的?
写在前面
所有AI应用的基本范式,都可以说:“先喂给它很多数据,然后让它找到其中的特征和规律,最后让它生成新的数据”,而AI绘画也不例外,通过扔进去大量真实的图片让AI不断去了解、认识和学习,然后根据训练效果,自己生成图片。 - 废话文学
下面主要通过白话的方式阐述AI绘画原理,适用于泛AIGC爱好者阅读和学习了解,算法原理略去了很多细节。目的是让大家大概明白了AI绘画是如何工作的,共勉。本文主要将以 Stable Diffusion 的为例讲解 AI 绘画的基本原理。
| 术语 | |
|---|---|
| Diffusion Mode | 扩散模型是一种深度学习模型,被设计用来生成与训练数据相似的新数据。 |
| LDM(Latent Diffusion Mode) | LDM潜在扩散模型是扩散模型的一种变体 |
| CLIP(Contrastive Language-Image Pre-Training) | CLIP 是一种用于匹配图像和文本的预训练神经网络模型 |
| U-Net | U-Net是一种U型结构的用于图像分割的神经网络模型 |
| VAE( variational autoencoder) | VAE 变分自编码器是一个生成模型,一种无监督的学习数据分布方法, |
背景
当前AI绘画的效果(普通人输入一句话,几秒钟画出来的作品):

现在的 AI 绘画工具集,也是五花八门…

AI 工具集导航网站:
基本原理
AI绘画原理可以简单概括为”降噪画图“,即:先随机生成一张马赛克图片,然后根据文字描述逐步去除马赛克,最终将能看清图片展示出来就可以了,这好比随机给了AI一块石头,让他按照你的描述去雕刻出一个作品。
给你3s停留时间,请将这句话在心中重复几遍,可以大声念出来,让我看看那个显眼包不好好听讲!!
其实上面所说的“马赛克图片”,只是我给它起的小名,它的大名中叫“噪声图”。
AI绘画的过程可以分为2个步骤:
步骤1: 理解语义,怎样学习文字描述和图片的联系;
步骤2: 生成图片,基于噪声图+描述生成图片;
移除像素 Vs 添加噪声?
因为直接移除像素会导致信息丧失,添加噪声则可以让模型更加学习到图片的特征。
通过上面的表述,可以拆解成了几个核心问题,只要搞清楚这五个问题,相信你AI绘画的底层逻辑也就清晰了。
问题1:AI是怎么知道文字描述的是什么?
首先大家要明白,机器其实并不会理解人类的语言,我们需要通过喂给它各种各样的图片数据,计算机会通过分析这些图片的特征,学习它们的风格和结构 。本质上要解决的问题是:如何将输入的一段话,就转换成了这次生成图像所需要的全部特征向量。
这里面就不得不提,在21 Openai年推出的OpenCLIP,OpenCLIP 的出现彻底打通了文字和图像之间的鸿沟。它的作用就是把文字和图像联系起来。
CLIP
如何构建一个庞大的图文数据库?
模型训练需要非常多的图片,数据从哪里来?
爬取信息:通过爬虫脚本抓取大量图片
打标签:每爬到一张图片后,都从许多维度来描述这个图,给图片打上对应的标签以及描述。实际上,大多是根据从网络上抓取的图像以及其 “alt” 标签进行训练的。
存储图文信息对:根据这些信息构建出一个超多维的数据库,每一个维度都会和其他维度交叉起来,此时相似的维度会相对靠拢在一起。 最终构建了一个超多维的数据库,包含上亿的“文本+图片”的信息对。
如何建立文本和图像的关联?
有了数据库,如何提供文本图像匹配能力,需要是不断地通过大量数据来训练CLIP去关联、认识图片和文字,并且根据和答案的比对,不断地矫正,最后达到精确匹配关键词和特征向量。
训练时用一组组文字和图像做对比, 通过文本编码器和图像编码器,分别的得到文本特征和图像特征。拿图像和文本编码后的特征去计算出一个相似性矩阵。这样训练后,当我们录入一段文本描述,CLIP模型就会根据描述去数据库里从多个维度进行相似度的匹配。当找到最相似的维度描述后,把这些图像特征全部融合到一起,构建出本次要产出的图像的总特征向量集。
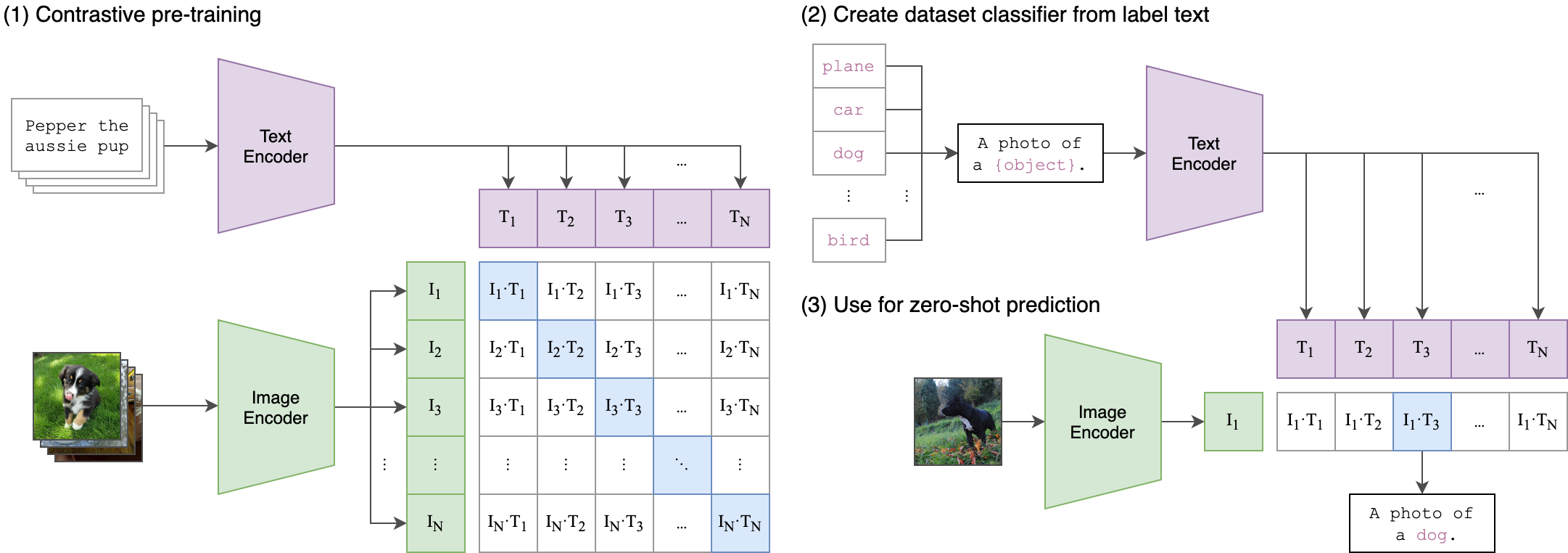
简要流程:
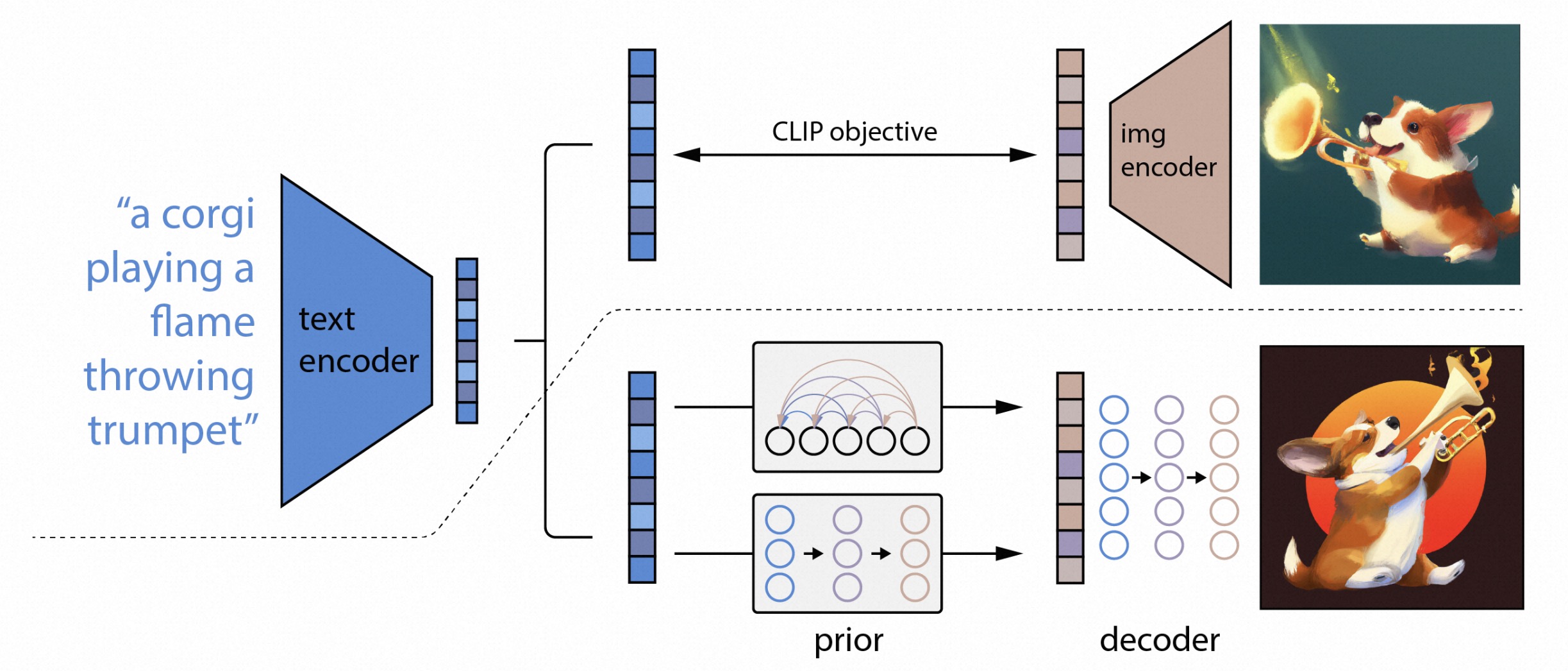
特别注意:我们可以直接用训练好的 clip 模型的文本编码器,这样当我们输入的一段话,就转换成了这次生成相关的文本特征向量,也就是所谓的“AI已经理解了你想画什么样的画了”。
问题2:原始的噪声图是怎么来的?
噪声图是Diffusion Model(扩散模型)生成的,那 Diffusion Model(扩散模型)又是什么?
Diffusion Model
目前主流AI绘画工具图片生成的核心都是扩散模型。特别说明,Diffusion Model 的应用不只局限于图片,其他音频、视频等场景也有。
扩散模型是在2015年相关论文里提出的, 主要包含2个过程,分别是前向扩散和逆向扩散,具体如下图所示:
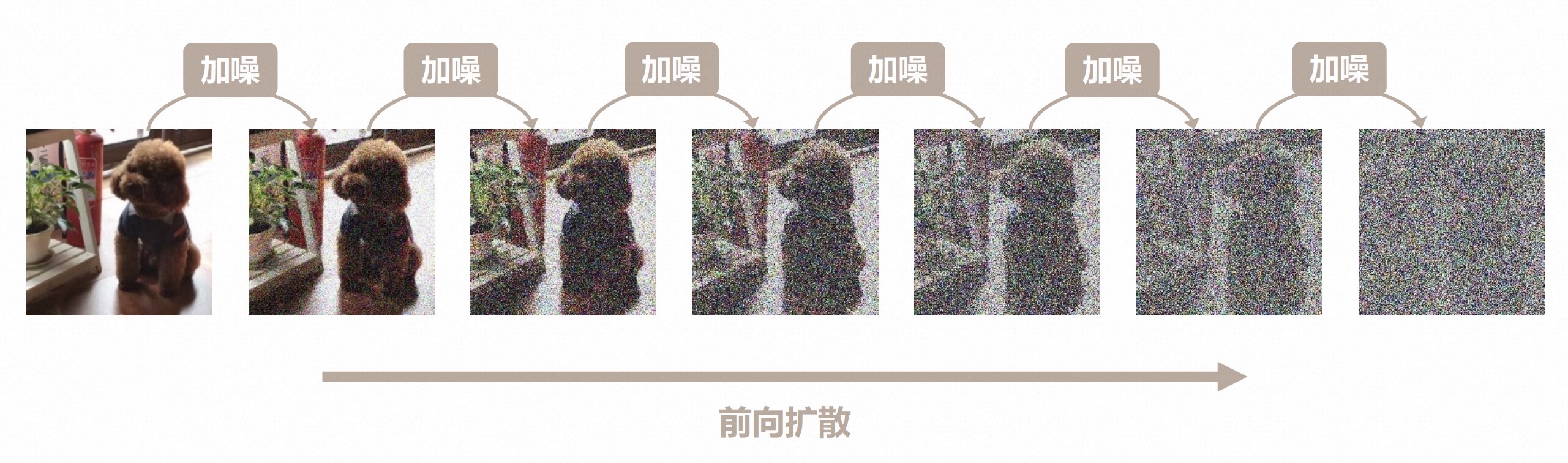
前向扩散:是一个通过算法不断叠加噪声的过程,可以简单理解为不断对图片进行马赛克处理。如图从右到左做模糊处理,直至最后看不出来是什么;
这个过程可以想象成你在发朋友圈照片时,想屏蔽一些信息,所以使用“编辑”功能不断地对某些区域进行涂抹,直到这个区域看不清原本的内容了。
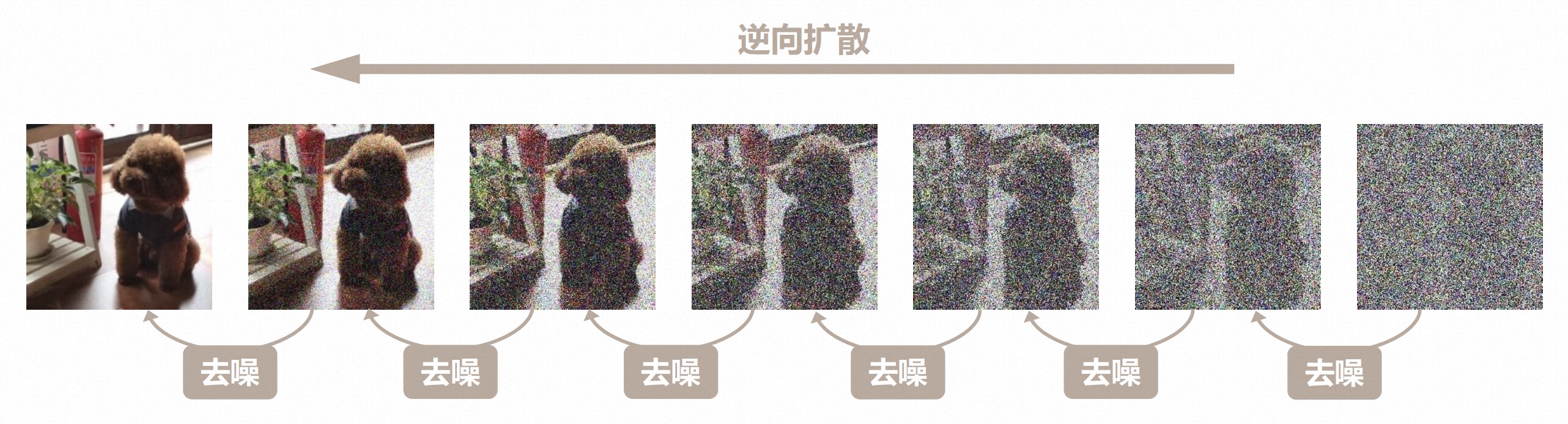
逆向扩散:是一个去噪推断过程。如图从左到右做处理,一步步把一个图片逐渐去除噪声,变清晰的过程。逐步朝着目标图像进行演变 。
问题3:如何根据噪声生成图片?
毫无疑问,逆向扩散的想法既巧妙又优雅, 但如何实现它呢?首先需要让AI知道图像中添加了多少噪声,教其预测噪声
如何训练一个噪声预测器(noise predictor)?
主要通过 U-Net 模型 + Scheduler 的组合,具体的训练过程如下。
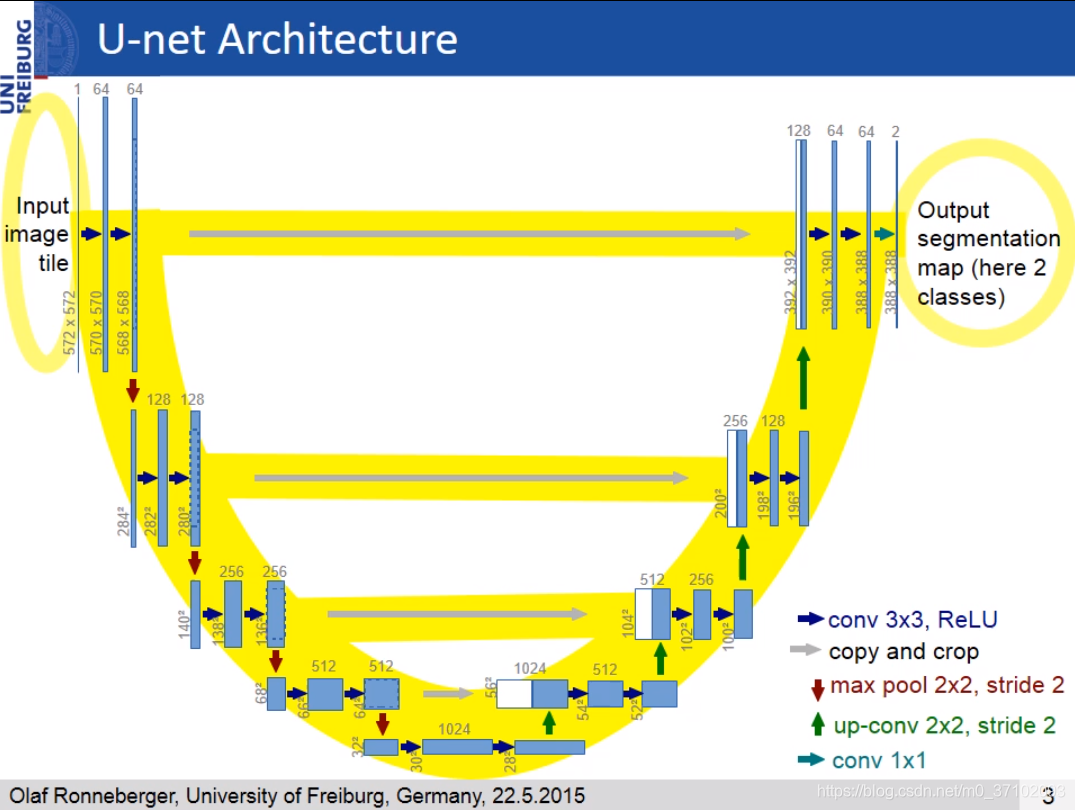
U-Net
U-Net在不断的训练过程中主要学会了一件事,那就是去噪!去噪!还是tmd去噪!
Stable Diffusion中U-Net的训练一共分四步:
随机选取一个示例:从训练集中选取一张加噪过的图片和噪声强度。
预测标记出无用的噪声:将数据输入U-Nnet,并且预测噪声矩阵。
与正确答案对比:将预测的噪声矩阵和实际噪声矩阵(Label)进行误差的计算。
不断纠正:通过反向传播更新U-Net的参数。
本质是一个强化学习的过程。
U-Net 的大体结构如下:
Scheduler
例如选择一张猫的照片作为训练图像,最终生成一个随机噪声图像。通过在一定数量的步骤中加入这个嘈杂的图像来破坏训练图像。然后让它告诉我们添加了多少噪声。这是通过调整其权重并向其展示正确答案来完成的。
当我们试图在每个采样步骤中获得预期的噪声,这被称为噪声计划(Noise schedule)。我们可以选择在每一步减去相同数量的噪声,也可以在开始时减去更多的噪声。

采样器在每一步中减去足够的噪声,以达到下一步的预期噪声。这就是您在逐步的图像中看到的内容。
虽然这个步骤无法做到图片生成,但对训练样本分类准确性至关重要。经过训练后,我们有了一个能够估计图像中添加噪声的噪声预测器。
噪声算法
即噪声的算法此前是依据正态分布给图像逐步增加噪声,到了2020年加噪声的过程被改为根据余弦相似度的规律来处理。
如何使用噪声预测器?
首先生成一个完全随机的图像,并请噪声预测器告诉我们噪声;然后我们从原始图像中减去这个估计的噪声。重复这个过程几次。你将得到一张猫或狗的图像。
-20231003162740453.png)
这里看下看下不断预测噪声的整个过程:
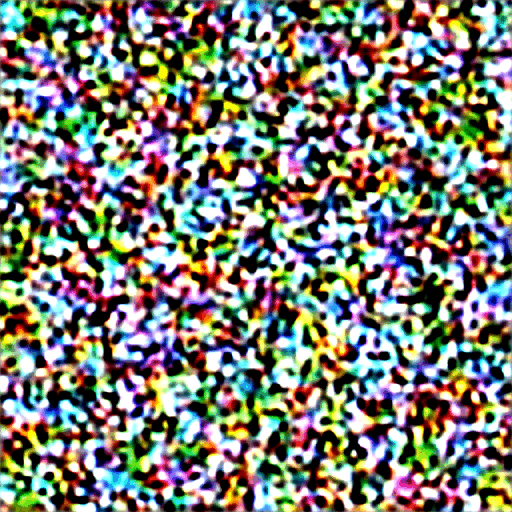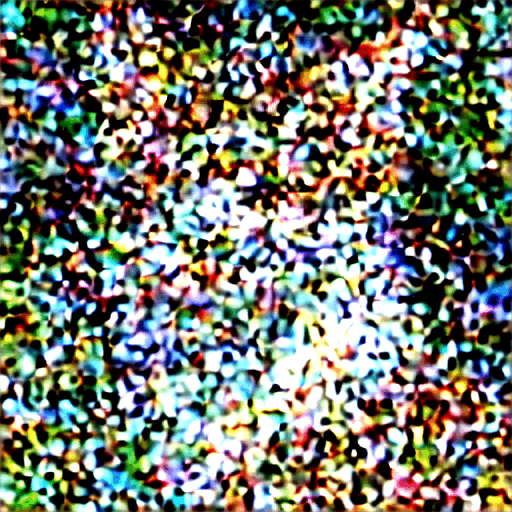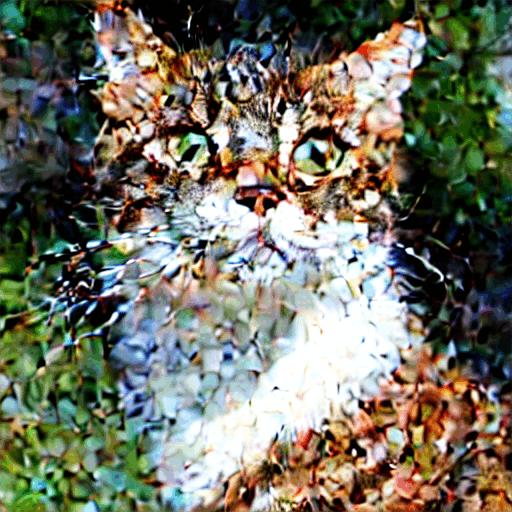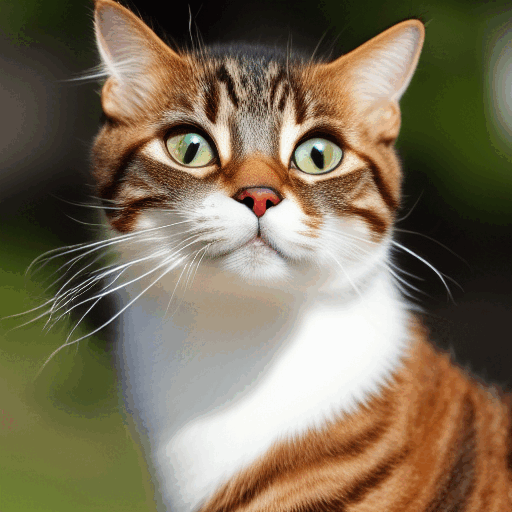
问题4:如何根据描述去除无用噪声?
AI是怎么能够按照我描述的来去除无用的噪声,其实这就是一个模型训练的过程。目的引导噪声预测器,使预测的噪声在从图像中减去后能给我们想要的结果。
为了加入文本特征, U-Net 里添加了注意力机制。
通过一个无分类器引导(Classifier-Free Guidance,CFG)的方法,放大具有文本特征的噪声,达到加强引导生成具有文本特征的图片的效果。

看看在每一步中添加了什么信息。

https://jalammar.github.io/images/stable-diffusion/diffusion-steps-all-loop.webm
问题5:如何提升运算效率?
由于上面的扩散过程是在图像空间中进行的。而图像空间非常庞大,导致计算上非常非常慢。
想想看:一个512×512的图像有三个颜色通道(红、绿和蓝),是一个786,432维的空间!(你需要为一个图像指定这么多值。)我们可以使用了一些技巧,让扩散模型位于像素空间来加快模型的速度,但仍然不够。
解法就是降维数据运算!
LDM(Latent Diffusion Mode)
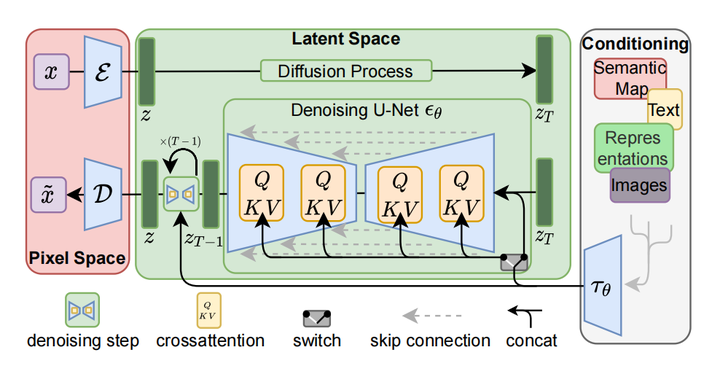
LDM 主要区别在于它通过压缩图片降低维度,压缩后所在的空间,叫潜在空间。这令计算量大幅度减少,降低了对硬件的要求。
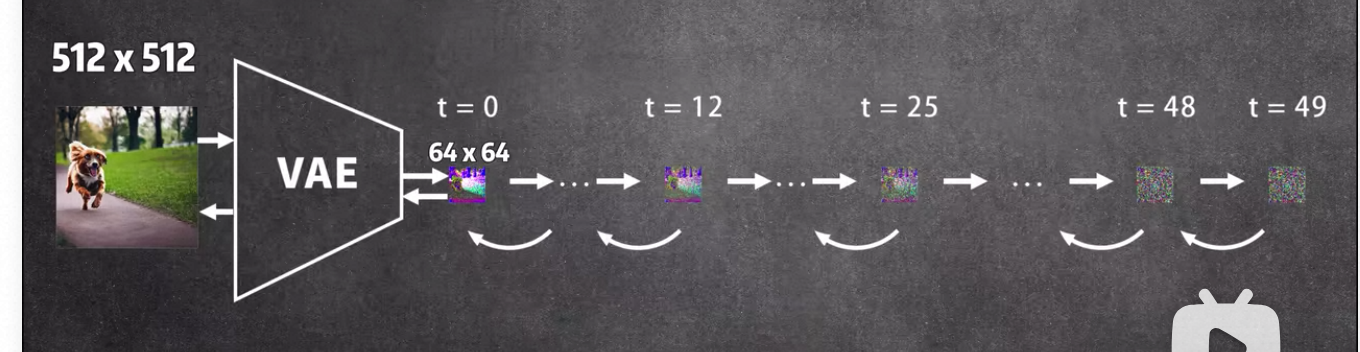
VAE( variational autoencoder)
LDM 模型将将图像压缩到潜在空间,是通过变分自编码器VAE( variational autoencoder)技术来实现的
VAE 主要通过编码器生成特征,然后解码器重构出原来的特征,让重构出来的特征和输入的特征尽可能相似即可。
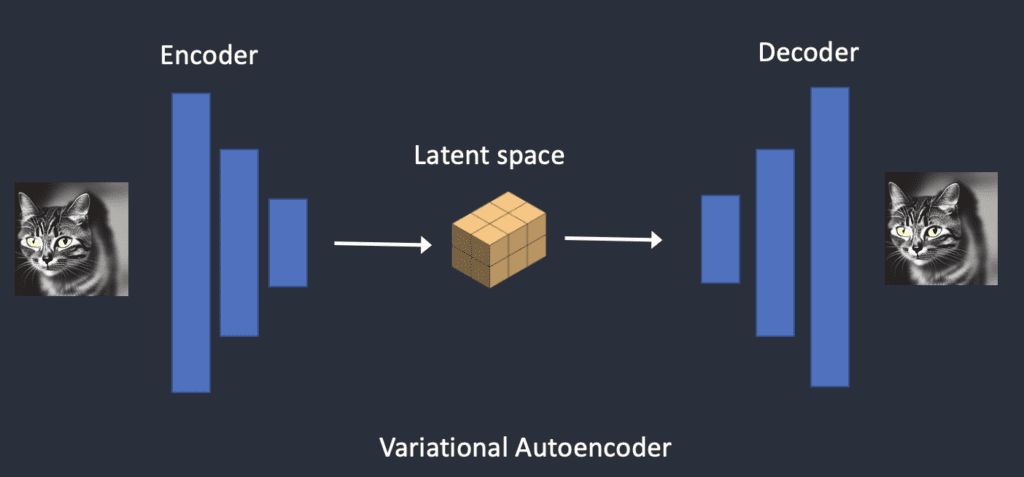
具体过程如下:我们先通过 VAE 编码器把图片压缩到潜在空间,然后在潜在空间中训练扩缩模型。
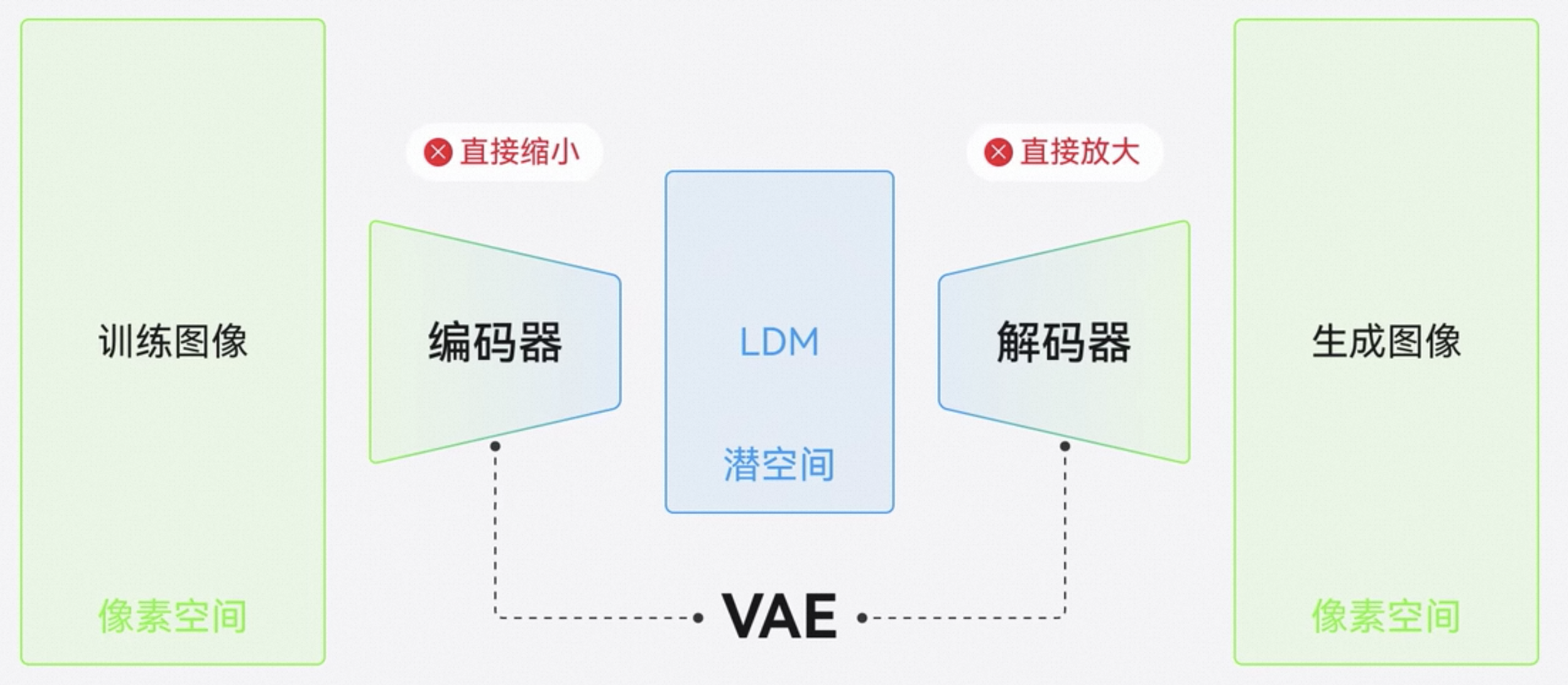
但压缩还原是还是那边有些失真。

注意:
VAE生成不只简单重构原来的特征,生成的特征是根据分布的均值。
VAE 是预先训练好的,LDM 可以直接拿来用。
问题6:如何稳定控制出图效果呢?
目前大模型最不可控的地方就是它的不稳定性。那么如果想要稍微控制下AI绘画的效果,有什么好的方法吗?这里给出四种方式,供大家参考。
##调整描述
本质上是改变通过文本匹配到的图像特征向量集合,所以最终的出图会不断地调整、优化。
垫图(img2img)
主流的AI绘画软件和模型都支持垫图功能,也就是你上传一张图,然后根据你这张图的轮廓或者大概样式,再生成一张图。
本质是在样图加噪声,然后拿这个叠噪后的图片作为基础再让AI进行去噪操作,所以最终风格、结构和原图相似的概率很大。概率上叠加的噪声越少,越和原图相似。
修改参数
通过插件中设置的条件或要求来控制生成的效果。
本质上它把去噪模型整个复制了一遍,然后两个模型并行处理,一个做常态去噪,一个做条件去噪,最后再合并,达到稳定控制的效果。
自建图库
当然你也可以自己建个图像库,单独拿大量数据训练,然后不断地训练大模型去识别这些图像,本质上对已有模型的微调
小结
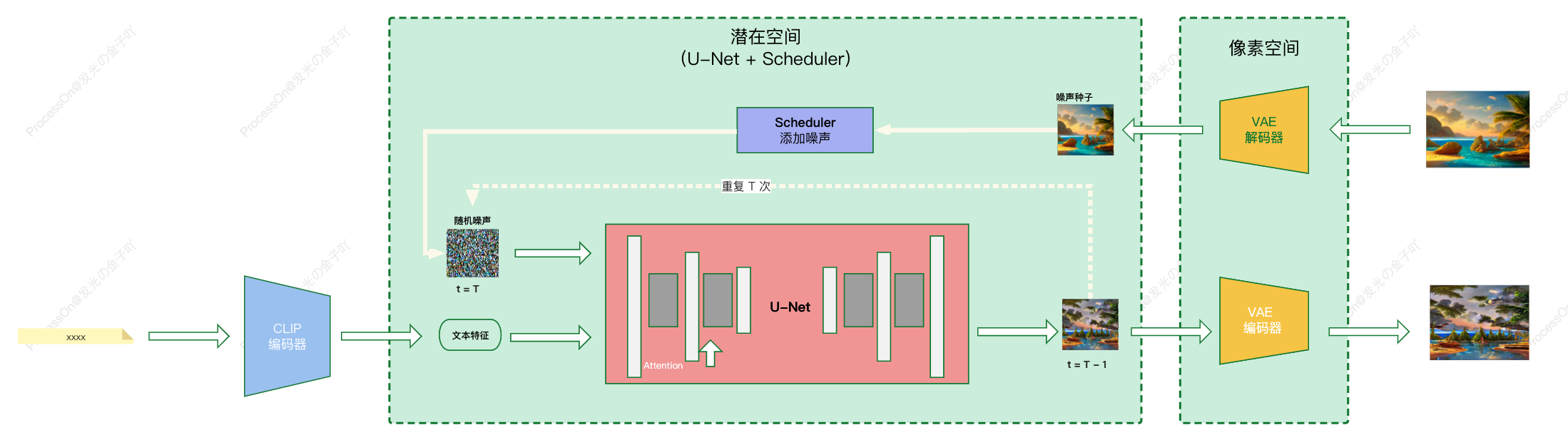
利用 CLIP 模型的编码器,把文字转换成向量作为输入;
通过 Diffusion Model 生成图像特征;
通过 VAE 模型的解码器,把图像特征还原成图片。
.png)
由此,我们可以看到三个主要组件(每个组件都有自己的神经网络):
通过 Clip 文本编码器,把文字转换向量;
输入:文本。
输出: 77 个标记嵌入向量,每个向量有 768 个维度。UNet + Scheduler,用于在信息(潜在)空间中逐步处理/扩散信息。
输入:文本嵌入和由噪声组成的起始多维数组(数字结构化列表,也称为张量)。
输出: 经过处理的信息数组
注:U-Net并不直接输出无噪声的原数据,而是去预测原数据上所加过的噪声。
- 通过 VAE 解码器将信息数组绘制最终图像。
输入: 处理过的信息数组(维数:(4,64,64)
输出: 生成的图像(尺寸:(3, 512, 512),即(红/绿/蓝、宽、高)
一点思考
AI 只是一个能够提高生产力工具而已,目前还是存在很多问题,例如 AI 绘画风格有些相似,因为便于计算,一些细节还是很粗糙,例如:人物的手、图片的文字不清晰等等。

其实目前的 AI 所具备能力其实很基础,但之所以认为为之惊叹甚至恐慌,某种程度上,只是人们对创造力的获取看的很难,然而事实并非如此。
人所具有创造力只是一种很原始的基础能力而已,通常的创造力,都是基于原有知识的创新,即:旧东西新组合。而更为强大的创造力,如:相对论、量子计算机等,这种创造来源未知。而AI都是基于既有知识训练,不太能具备此种创造力。
此外,不会存在通用上的AI,未来一定是针对某一领域的具体式AI,如:文字-聊天,图像-绘画,声音-音乐等,作为人类的助手形式存在。不必执着于过去,因为改变终将到来!
参考资料
[视频]Stable Diffusion 原理介绍:
https://www.bilibili.com/video/BV1vV4y1D7LP
https://www.bilibili.com/video/BV1Yu411x7mg
https://www.youtube.com/watch?v=1CIpzeNxIhU
[文章]Stable Diffusion 原理介绍:
https://stable-diffusion-art.com/how-stable-diffusion-work/
https://www.modevol.com/episode/clfwjxyw92kql01mu7j6i8q6w
https://jalammar.github.io/illustrated-stable-diffusion/
CLIP模型介绍:https://github.com/openai/CLIP
OpenCLIP模型介绍:https://github.com/mlfoundations/open_clip
Textual Inversion 介绍: https://textual-inversion.github.io/
U-Net 介绍:https://zhuanlan.zhihu.com/p/642354007
各种微调模型方法对比:https://www.youtube.com/watch?v=dVjMiJsuR5o
Diffusion Models 公式 https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
Latent Diffusion论文:https://arxiv.org/pdf/2112.10752.pdf
DALLE2论文:https://cdn.openai.com/papers/dall-e-2.pdf
LoRA论文:https://arxiv.org/pdf/2106.09685.pdf
Dreambooth 论文:https://arxiv.org/pdf/2208.12242.pdf
ControlNet 论文:https://arxiv.org/pdf/2302.05543.pdf