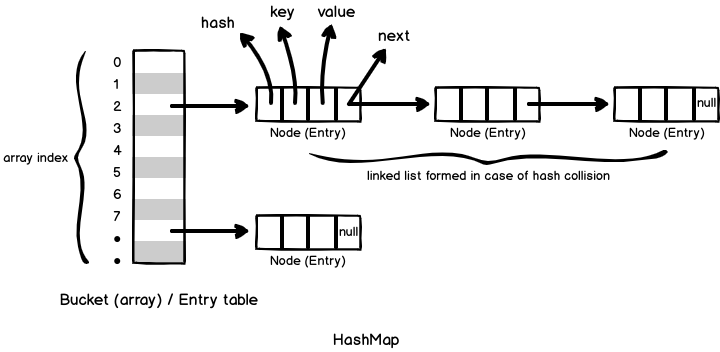
为什么覆盖 equals() 一定要覆盖 hashCode()
概述
为什么在重写equals的方法的时候,必须注意重写hashCode方法?为什么要保证通过equals判断相等的两个对象,调用hashCode方法要返回同样的整数值。 如果不能保证会有什么问题?
请听下回分解-_-..
解:如果不这样做的话,就会违反 hashCode 的通用约定,(相等的对象必须拥有相同的 hashCode 散列值),从而导致该类无法同所有的给予散列的集合一起正常运作。这类集合包括 HashSet、HashMap。
详述
举例说明问题:
1 | public class PhoneNumber { |
此时,你可能希望 numberMap.get(new PhoneNumber(707,867,5309)) 会返回 “Jerry”,但它实际上返回的是null 。这里会涉及到两个实例:第一个实例是第一次添加进入的 PhoneNumber , 它会被添加到一个桶中。因为没有重写 hashCode 方法,所以你取的时候是去另外一个桶中取出来的 PhoneNumber 实例,所以自然两个实例不相等。因为 HashMap 有一项优化,可以将与每个项相关联的散列码缓存起来,如果对象散列码不相等,也就不再去检验对象的等同性。在深入的说,插入时以当前对象hashCode做为存储位置依据,查询时因新对象hashCode值和插入时的对象hashCode值不相等,导致没法查找的位置不对,无法正确找到元素。
修正这个问题非常的简单,只要提供一个相等的散列码就可以了。
下面是解决办法:
方法1
- 声明一个 int 变量并命名为 result,将它初始化为对象中的第一个关键域散列码 c.
- 对象中剩下的每一个关键域 f 都完成一下步骤:
为该域计算 int 类型的散列码 c,然后按照下面的公式,把散列码 c 合并到 result 中。
_result = 31 _ result + c;*
① 如果该域是基本类型,则计算 Type.hashCode(f),这里的 Type 是集装箱基本类型的类,与 f 的类型相对应
② 如果该域是一个对象引用,并且该类的 equals 方法通过递归地调用 equals 的方式来比较这个域,则同样为这个域递归地调用 hashCode 。如果为null ,则返回0
③ 如果该域是一个数组,则要把每一个元素当作单独的域来处理。也就是说,递归地应用上述规则,对每个重要的元素计算一个散列码,然后根据步骤2 . b中的做法把这些散列值组合起来。如果数组域中没有重要的元素,可以使用一个常量,但最好不要用0。如果数组域中的所有元素都很重要,可以使用 Arrays.hashCode 方法。 - 返回result
写完了之后,还要进行验证,相等的实例是否具有相同的散列码,可以把上述解决办法用到 PhoneNumber 中:
1 |
|
如果一个类是不可变的,并且计算 hashCode 的开销也大,那么应该把它换存在对象内部,而不是每次请求都重新创建 hashCode。你可以选择"延迟初始化" 的散列码。即一直到 hashCode 被第一次使用的时候进行初始化。如下:
1 | private int hashCode; |
虽然上述给出了 hashCode 实现,但它不是最先进的。它们的质量堪比 Java 平台类库提供的散列函数。这些方法对于大多数应用程序而言已经足够了。
方法2
Objects 类有一个静态方法,它带有任意数量的对象,并为它们返回一个散列码。这个方法名为 hash 。你只需要一行代码就可以编写它的 hashCode 方法。它们的质量也是很高的,但是,它的运行速度相对慢一些,因为它们会引发数组的创建,以便传入数目可变的参数,如果参数中有基本类型,还需要装箱和拆箱。例如:
1 |
|
方法3
如果不想那么费力,可以直接使用 eclipse 或者 Idea 提供的 AutoValue 自动生成就可以了。
遵守重写约定
当你要重写对象的 hashCode 方法时,下面这两个约定我希望你能遵守:
不要对 hashCode 方法的返回值做具体的规定,因此客户端无法理所当然地依赖它;这样可以为修改提供灵活性。
不要试图从散列码计算中排除掉一个对象的关键域来提高性能。
总而言之,每当覆盖 equals 方法时都必须覆盖 hashCode。否则程序将无法正确运行。