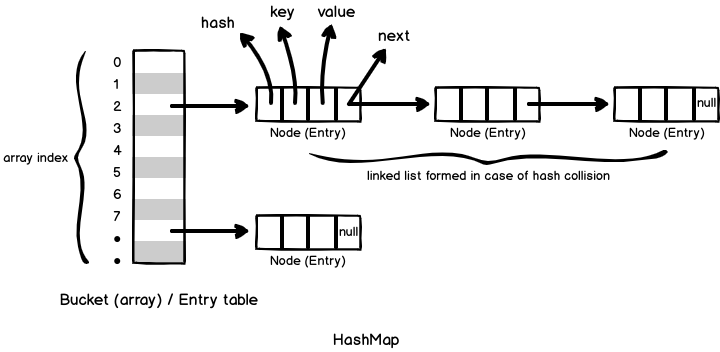
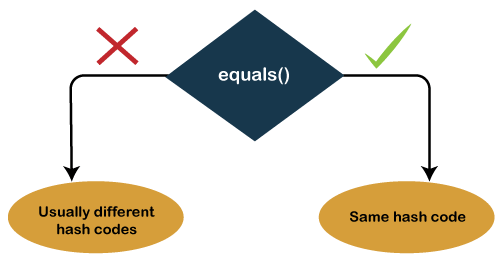
JUC 并发编程指南
JUC: 泛指java.util.concurrent包中并发编程下使用的工具类。
多线程编程的固定套路: 线程操作资源类
引言
Java线程有几种状态,分别是什么?
6种
New,Runnable,Blocked,Waiting, Timed-Wating,Terminated
wait/sleep的区别?
sleep - 谁调用谁睡觉😴
使用sleep()来控制一个线程的执行时间,使用wait()来进行多线程同步。
| wait | sleep | |
|---|---|---|
| 所属类不同 | Object | Thread |
| 是否释放锁 | 线程休眠并且释放掉对象机锁 | 线程休眠并且不释放对象机锁 |
| 使用范围不同 | 同步方法/同步代码块 | 任何地方 |
推荐:https://www.jianshu.com/p/41d4a7728fc4
Callable与Runnable区别:
| Callable | Runnable | |
|---|---|---|
| 是否有返回值 | 有 | 无 |
| 是否抛出异常 | 有 | 无 |
| 方法不同 | call() | run() |
1 | FutureTask task = new FutureTask<String>(new MyCallable()); //适配模式 |
JMM( Java内存模型)
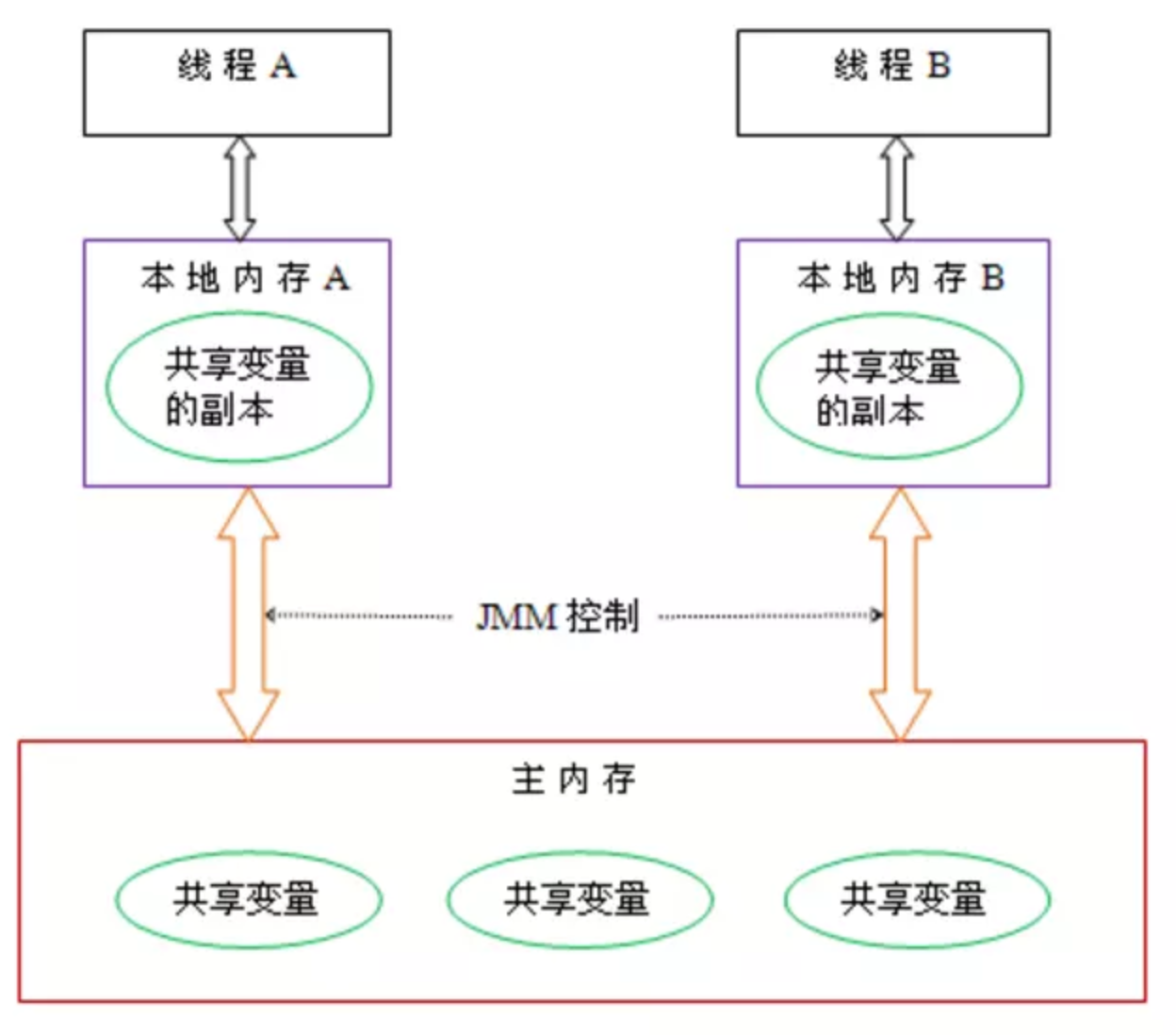 JMM控制Java线程之间的通信,决定一个线程对共享变量的写入何时对另一个线程可见。本质上`JMM定义了线程和主内存之间的抽象关系:`
每个线程的本地内存是JMM的一个抽象概念,并不真实存在,它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。
JMM控制Java线程之间的通信,决定一个线程对共享变量的写入何时对另一个线程可见。本质上`JMM定义了线程和主内存之间的抽象关系:`
每个线程的本地内存是JMM的一个抽象概念,并不真实存在,它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。
Volatile
- 保证可见性 - 没从都从主内存中读取共享变量
- 可防止指令重排
- 不保证原子性 - 如果需要变量操作的保证原子性,可以采用AutomictInteger等类解决
CAS - 比较并交换
CAS(compareAndSwap): 比较并交换,它是一个CPU的并发原语,是一个原子性的内存级别的操作,本身就不会存在数据不一致的问题;
- 它的功能:判断工作内存中的某个位置,是否是预期值,如果是就更新为指定的值。即:比较当前工作内存中的值和主内存的值,如果相同,就执行操作
- Unsafe类是实现CAS的核心类,它可以操作特定内存中的数据(本质是调用native方法)
1 | // valueOffset - 内存偏移量 |
- CAS缺点:
循环时间长,开销大;只能保证一个共享变量的原子操作
存在ABA问题:即A被置为B后,B再被置为A,但是线程是无法感知的交换的。
ABA问题产生的原因:CAS算法的前提是取出内存中某个时刻的数据,并且比较并交换,在这个时间差内有可能数据被修改!因此尽管CAS操作成功,但是不不代表这个过程就是没有问题的!
AtomicStampedReference - 原子引用
可以用它来解决ABA问题,原理类似数据库乐观锁;利用版本号,来识别是否被修改过。
1 | //1. 获得版本号 |
锁
公平锁和非公平锁
- 公平锁:就是非常公平,先来后到
- 非公平锁:就是非常不公平,可以插队!有时候插队可以提高效率
- 两者区别
公平锁:并发环境下,每个线程在获取到锁的时候都要先看一下这个锁的等待队列!如果为空,那就可以占有锁!否则就要等待。
非公平锁:上来就直接尝试占有该锁!如果失败就会采用类似公平锁的方式!
synchronized :默认就是非公平锁,改不了
ReentrantLock :默认就是非公平锁,可以通过参数修改!
1 | public ReentrantLock() { |
synchronized和lock的对比
synchronized关键字可以和对象的机锁交互,来实现线程的同步。 因此synchronized锁住是对象或类
类比记忆:车自动挡和手动挡的区别
| synchronized | lock | |
|---|---|---|
| 定义 | 一个内置关键字 | 一个类 |
| 释放锁 | 自动释放 | 手动释放 |
| 判断获取锁 | 不能判断 | 可以判断 |
| 实现 | 可重入,不可中断,非公平的 | 可重入, 可以公平 |
Lock锁
Lock锁比synchronized使用范围更广泛。
1 | Lock lock = new ReentrantLock(); |
ReentrantLock - 可重入锁(递归锁)
白话:线程可以进入任何一个它已经拥有锁的,锁所同步的代码块!
大门 卧室A 卧室B 厕所
最大的好处:就是避免死锁!
ReentrantReadWriteLock - 读写锁
读写分离,提高效率!
读锁(共享锁)
写锁(独占锁)
1 | ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); |
死锁
产生死锁的原因:
1、系统资源不足
2、进程运行顺序不当!
3、资源分配不当!
发现死锁
1 | //查看进程号 |
常见并发问题
生产者消费者问题
- synchronized
- ReentrantLock
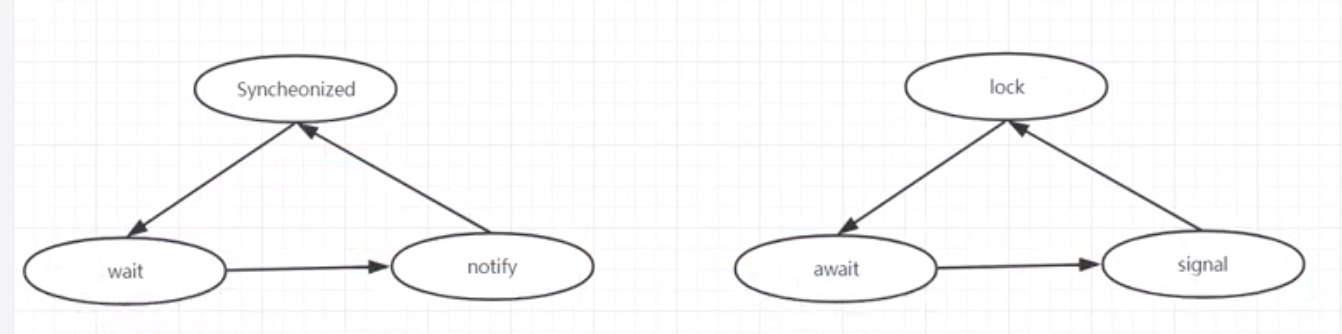
多线程间精确通知访问顺序
通过一个精确通知顺序访问的案例加深对Condition的使用。
通过给每个线程不同的condition,然后用condition.signal()精确地通知对应的线程继续执行。
并发工具类
信号量 - Semaphore
作用: 限流管理公共资源
1 | Semaphore semaphore = new Semaphore(3); |
可并发集合类
1 | List - CopyOnWriteArrayList | Collections.synchronizedList(list1); |
注:
- CopyOnWriteArrayList的写操作性能较差,而多线程的读操作性能较好。
- Collections.synchronizedList写操作性能较好,而多线程的读操作性能较差(因为是采用了synchronized关键字的方式)。
计数器
减法计数器 - CountDownLatch
1 | CountDownLatch downLatch = new CountDownLatch(6); |
队列
阻塞队列 - ArrayBlockingQueue
- 四组API:
| 当队列满时,处理方式 | 抛出异常 | 返回boolean值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入 | add | offer | put | offer(e,time,timeUnit) |
| 移除 | remove | poll | take | poll(e,time,timeUnit) |
| 检查对头 | element | peek | - | - |
同步队列 - SynchronousQueue
一种比较特殊的队列形式;每一个put操作,必须等待一个take,否则无法继续添加元素;
线程池 - ThreadPoolExecutor
运用池化思想,控制运行的线程的数量,处理的时候可以把一些任务放入队列 ;
特点:实现线程的复用!控制最大并发数!
7大参数
1 | ThreadPoolExecutor(int corePoolSize, |
3大方法
1 | Executors.newSingleThreadExecutor(); |
强烈不建议使用: 存在OOM的隐患;
4种拒绝策略
AbortPolicy (默认的:队列满了,就丢弃任务抛出异常!) - 队列add()
CallerRunsPolicy(哪来的回哪去? 谁叫你来的,你就去哪里处理)
DiscardOldestPolicy (尝试将最早进入队列与的任务删除,尝试加入队列)
DiscardPolicy (队列满了任务也会丢弃,不抛出异常) - 队列offer()
流程图: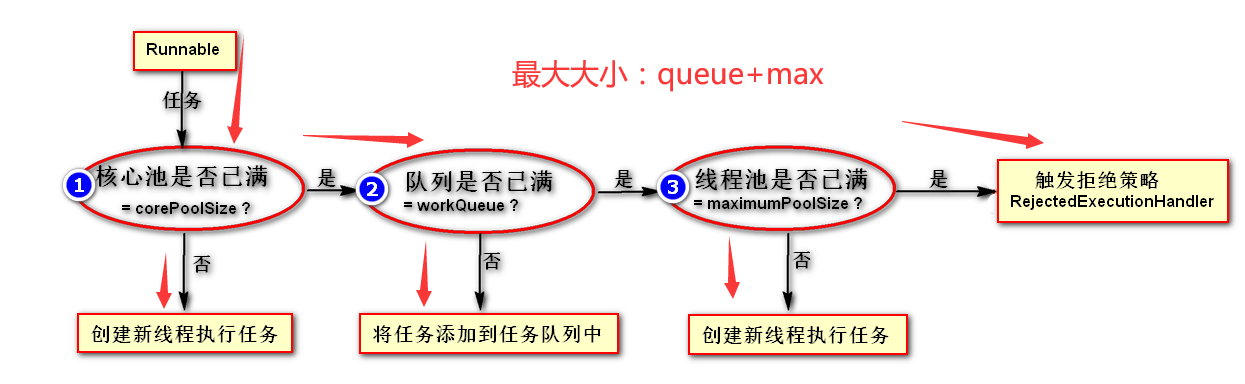
- 最大参数该如何设置?
CPU 密集型:CPU设置,每一次都要去写吗?
IO 密集型:磁盘读写、一个线程在IO操作的时候、另外一个线程在CPU中跑,造成CPU空闲。
最大线程数应该设置为 IO任务数! 大文件读写耗时!单独的线程让他慢慢跑。
对象类型(轻软弱虚)
强引用
软引用:平时不清,当内存空间不足时,才会被回收;通常用于缓存;
弱引用:只要发生GC就会被回收;
虚引用:比弱引用还弱,获取都获取不到。
作用:管理堆外内存(会用一个队列来记录虚引用的回收对象,用一个线程来监控该队列,当检测到队列有值时,会进行相应操作)
ThreadLocal
线程本地对象,一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰,每个线程都有一个自己的Map;
Entry这个键值对,是一个弱引用对象:
为什么要将Entry这个键值对,是一个弱引用对象,而不是强引用?
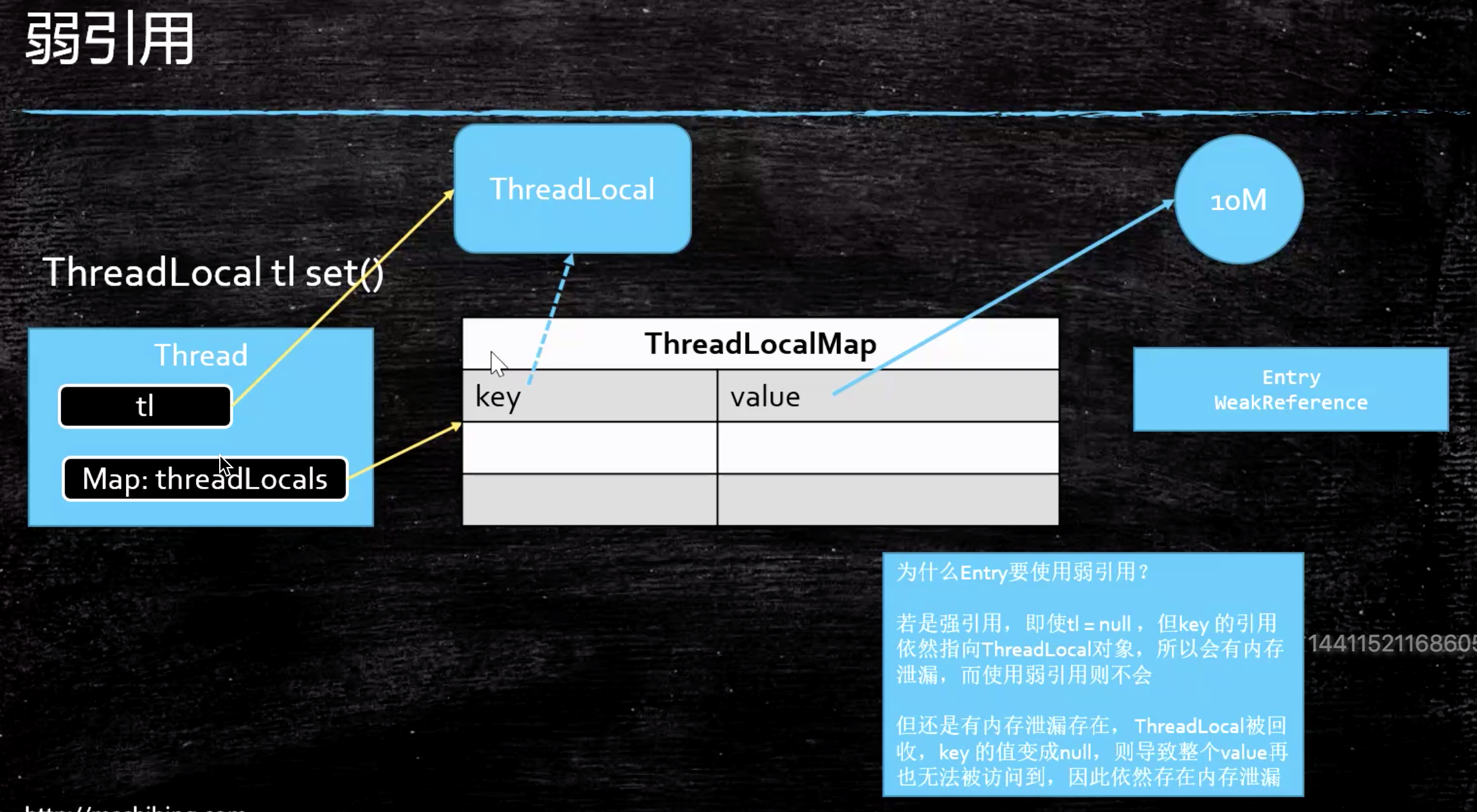
因此当ThreadLocal对象中数据不用时,要记得手动remove移除掉;
数据计算
函数式接口类型
- 函数型接口 [Function]:有一个输入,有一个输出
- 断定型接口 [Predicate]:有一个输入参数,返回只有布尔值。
- 供给型接口 [Supplier] : 没有输入参数,只有返回参数 (生产者)
- 消费型接口 [Consumer]: 有一个输入参数,没有返回值(消费者)
Stream流式计算
流(Stream)到底是什么呢?
类比数据库:保存数据 + SQL操作; 数据就是数据,计算交给Stream!,而集合就是数据,Stream管理计算。
计算操作
过滤 filter
映射 map
排序 sort
分页 limit
ForkJoin - 分支合并
ForkJoin是由JDK1.7后提供多线并发处理框架。ForkJoin的框架的基本思想是分而治之。任务切分,结果合并;适用于大数据计算的情况。
work-stealing工作窃取
- 为什么ForkJoin会存在工作窃取呢?
工作窃取:底层以双向队列为基础;任务A执行完自己的工作,会帮任务B处理它的任务,并且执行完毕后将任务归还给子任务B。这样就可以提高执行效率。
- 继承RecursiveTask类
- 适用ForkJoinPool中的invoke()方法执行任务
- fork() - 创建子任务
- invoke() - 执行任务
- join() - 返回结果
注:尽可能适用流式计算,比ForkJoin更高效!
了解更多:https://www.jianshu.com/p/ef2eb256840d
CompletableFuture - 异步回调
1 | Futrue设计初衷: 对将来发生的结果进行建模 |